如何进行前端自动化测试?
68 个回答

没人邀请,路过回答。
前端测试是前端工程方面的重要分支,有过一些探索,这里简单分享一下。
首先,还是要强调一点:
前端是一种特殊的GUI软件
看过我最近一年内做前端工程方面相关分享的人可能有印象,我总是在强调这一点。前端测试也跟这个理论基础有所关联。
在这里,我还想吐槽一下:
API测试方法论在测试GUI时并不能解决所有问题。
与很多前端工程师讨论过前端测试,大家更多的还是盯着API测试方法论。诚然,前端有那么一小部分代码是可以用API测试保证质量的,但前端项目中的绝大多数代码是GUI界面,前端测试应该向传统GUI测试方法论需求解决方案:
GUI软件测试_百度百科,这个百科词条介绍的很不错,大家可以感受一下GUI测试相关概念和方法。它的测试用例、覆盖率统计、测试方法等等都与API测试有着很大的不同。
统一了这个认知之后,我们来讨论一下前端GUI测试的特殊性。根据百科词条上的那些介绍,相信大家都能感觉到GUI测试的成本非常高,而前端这种特殊的GUI软件,具有天生的快速迭代特征,这使得case维护成本也变得非常高,经常跟不上迭代速度。
一个标准的互联网应用产品的前端部分,我粗略估计大概有20%的业务基础代码比较稳定,比如通用组件、通用算法和数据模块等,可以针对这些建立复杂一些的API和GUI测试用例来保证质量。剩下80%的部分不是很稳定,每天都在迭代,针对他们维护case的成本非常高。目前业界中号称做了自动化测试的项目,也大多是在做那稳定的20%。
关于稳定部分的单元测试方法我这里就不赘述了,
@貘吃馍香的答案给出了很多关键字,有兴趣的去搜索就好了。我想讨论的是针对剩下80%不稳定部分的工程化测试方案。据我了解,前端测试面对这些问题还是很无力的,业内大部分团队还是靠堆人解决。
面对这种现状,我其实也没想到过什么好的方法,基本原则就是:以最低的成本建立和维护自动化测试用例。到目前为止,就想到过两个方案(都不是测试方案,只是回归测试辅助):
1. 不太靠谱的“超级工位”大法。
这个方案可以说根本不是什么技术方案,而是一个办公设施,就是我们准备一个工位,摆上所有我们需要测试的主流设备,然后设备通过某种方式与一台电脑相连接,测试人员坐在工位上,在电脑中输入某个url,就能同步到所有设备中,然后开始逐个的人肉测试。


超级工位大法示意图(应该很多设备的,这里就是随便展示一下而已。。。)
相比现在的前端GUI测试,超级工位已经算是从0到1的飞跃了,虽然没解决什么技术问题,但为测试前的准备工作做好了铺垫。如果把前端测试比作吃屎,超级工位就是为这餐准备了一个好一点的餐桌。。。
2. 靠谱一些的“页面差异监控”
12年的时候还在百度,当时有同事去美国参加velocity,twitter分享了一下他们的开发流程,其中有一个环节就是页面对比监控,利用了一个叫pdiff的工具,每次提交代码,会自动对比页面之间的差异然后提醒测试人员注意回归。这也是一个典型的GUI测试零成本维护用例的案例。不过pdiff这个工具是基于像素对比的,误报率比较高,所以去年我做了一个这个项目:
fouber/page-monitor · GitHub基于DOM树的diff,这样就能很大程度上自主控制要监控的元素,可以设置监控样式、文本的变化,比起像素diff智能了一些。
其工作原理就是利用phantom或其他headless浏览器访问页面,然后截图,然后执行一段js,遍历整个dom树,获取元素计算样式和元素内文本内容,构造出一个JSON结构,然后每次diff这个json来判断页面差异,并标记在截图上展示。dom树的diff过程有点类似react的虚拟dom树diff。
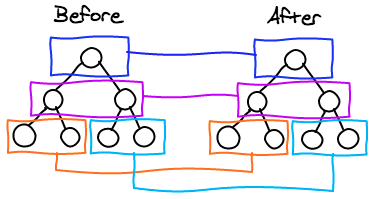
(react的dom树diff算法示意图)

(react的dom树diff算法示意图)
DOM树diff我们可以分辨出元素样式修改/内容修改/新增元素/删除元素四种不同的页面差异,我们可以配置选择器来忽略元素。四种页面差异的效果图:


新增元素(绿色区域标记部分,“i am new here”)
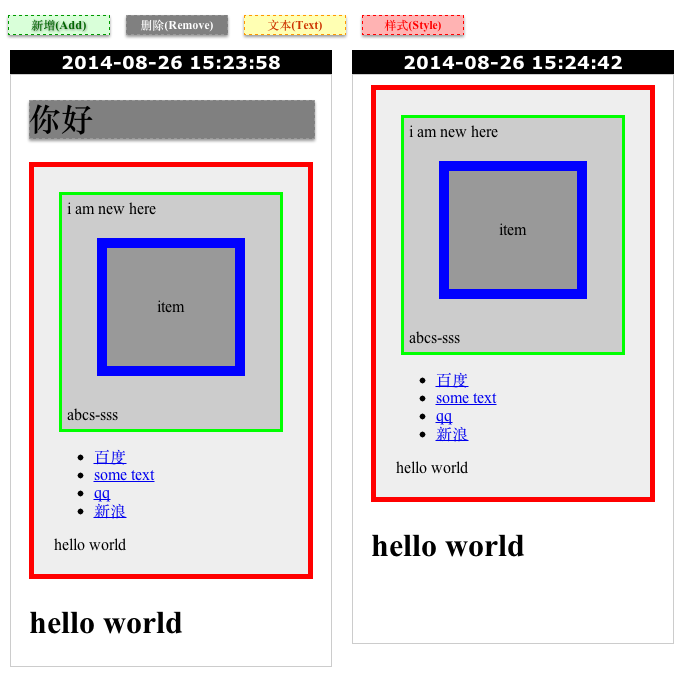

删除元素(灰色区域标记部分,“你好”)
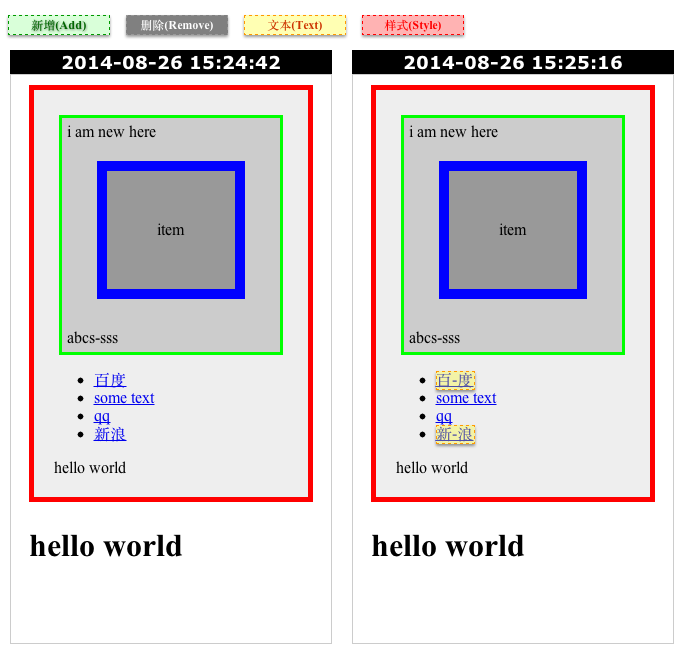

内容修改(黄色区域标记部分,“百-度”,“新-浪”)
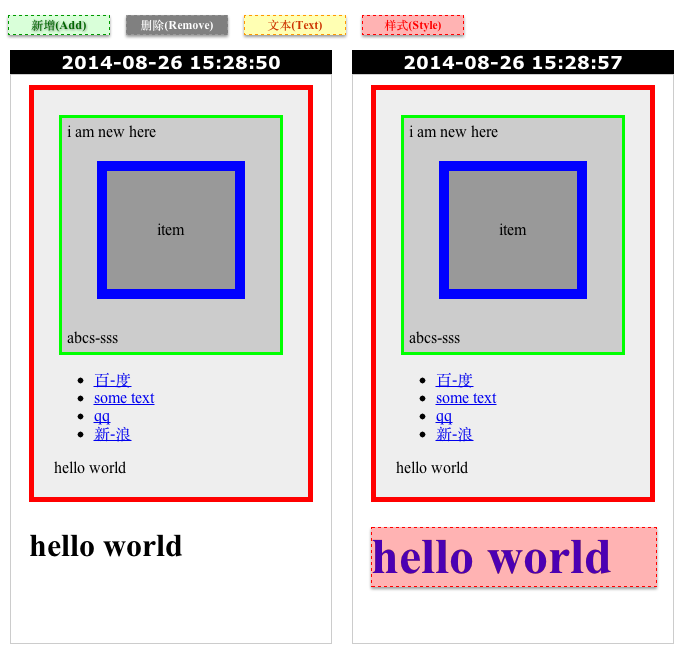

样式修改(红色区域标记的部分)
基于这样的页面差异对比监控,我们可以建立一个任务系统,把应用的所有页面url监控起来,这样每次版本迭代提交代码后,系统就能自动告诉我们,哪些页面的元素展现发生了改变,用于确定回归范围。
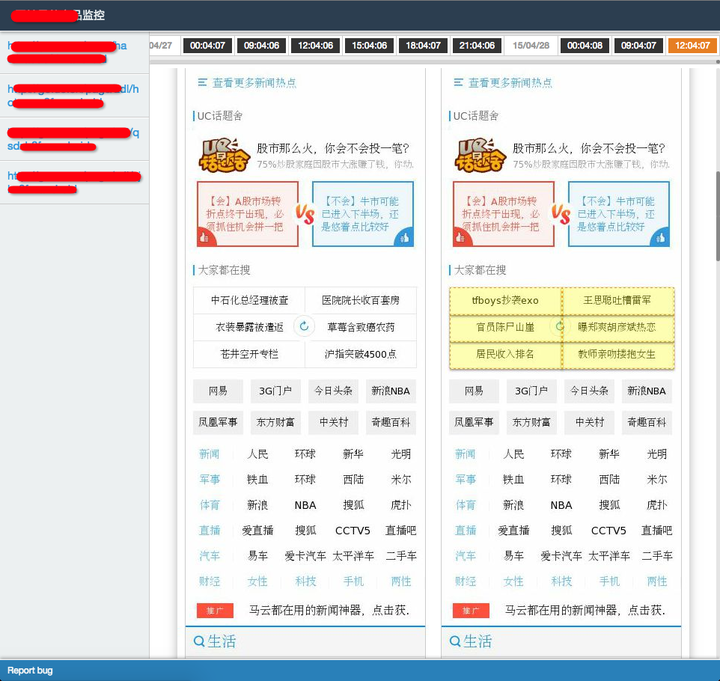

(目前我还只是把这个系统用于竞品或者自家产品的运营监控)
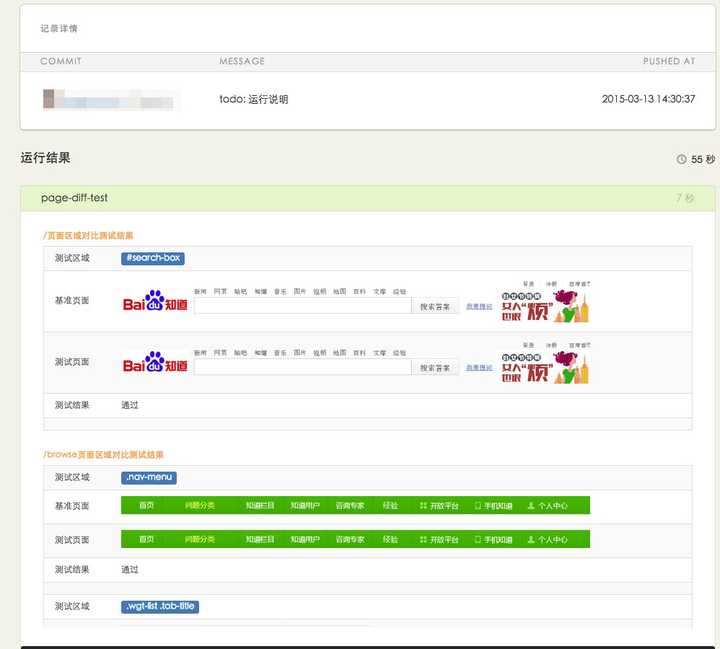

(百度
@FEX团队开发的基于像素diff的组件监控平台)
用监控的方式确定测试回归范围,是一种“少吃屎”的手段,符合工程化要求,能比较大范围的应用,虽然不能完美解决GUI中的交互问题,但能保证GUI的展现问题已经是不小的进步了。
=====[ 补充 ]=====
经评论中
@貘吃馍香大大的提醒,这里强调一下,页面差异监控的目的是方便的通知人肉回归范围,这并非测试方案,而是一种辅助测试的手段。

泻药
还有 Selenium 神马的吧
当然 berserkJS 兴许也能凑合干干这事儿(类似phantomjs )
个人认为一般前端自动化测试大致包括
- 类库单元测试自动化
- UI组件测试自动化
类库单元测试自动化
较好实现
基本思路是让不同的浏览器可以自动根据指令跑一些JS函数
结果与预期比对后返回是否通过case测试标志
其中一般有两种实现方式:
其一:
- 打开目标浏览器,运行测试框架站点
- 测试框架站点通过ajax 轮询、websocket 等方式,将待测 js 的 case 在浏览器内运行(通过eval 、createElement("script") 等方式)
- 比对测试结果,将结果 post 到远端
- 远端接受测试结果
- 远端等待所有浏览器返回结果完成
- marge 所有浏览器数据显示最终通过与否结果。
这种方式弊端:
- 人工开启一次所有浏览器
- 需要排队测试,浏览器只能一次运行完一组测试后才能再运行下一组
- 如果中间某testcase导致浏览器异常,返回结果将缺失,需要人工去服务器上检查下浏览器状态
好处:
- 可以覆盖所有想覆盖到的浏览器
另一种方式:
- 将常用浏览器内核放进一个或多个相互有关联的进程内
- 用例通过系统消息发送到各个包装的内核中
- 每次开启一个新内核进程运行JS用例
- 用例结果发送给包装进程
- 包装进程汇集所有用例结果后post到远端保存
- 包装进程连带内核进程一起退出
优点:
- 无序人工开启一次浏览器
- 独立进程运行,无需排队
- 不怕内核异常,异常后包装进程可以直接恢复内核或者通知测试失败
缺点:
- 前端实现太困难,需要C++开发
- 无法覆盖到所有浏览器
- 常用内核覆盖更新劳心劳力
UI组件测试自动化
这是个大坑
因为 UI 涉及可视化内容
需要实现不同 testcase 的自动化界面操作
常见的如,单双击、拖拽、自动表单内容填写等
一般用 Selenium 来录操作后执行
或者使用 phantomjs 等工具写模拟操作脚本来实现
这类东西一般就不太指望能跨全平台了,一个浏览器能跑通就不错了。
======
针对这个稍微补充
比如
@张云龙说的方法,也只能针对 phantom 之类 qtwebkit 核来作简单页面 diff 展示情况对比。
它不能解决实际复杂情况:
- 针对不同浏览(或不同网络情况)中断吐出内容不一致(想象wap,虽然过时了)
- 个人登录后吐出内容不一致(社交网络)
- 根据地域不同吐出内容不一致(百度搜索框计算什么的)
- 其他等等
大致问题了解下就好了
====
主要是 UI 的 testcase 写起来太烦
而且 UI 还是最善变的
一般公司不去做这种费力不讨好的自动化测试
基于 phantomjs 的自动化测试
它主要靠js脚本来模拟操作
一般流程是写代码写代码写代码
- open 某个 url
- 监听 onload 事件
- 事件完成后调用 sendEvent 之类的 api 去点击某个 DOM 元素所在 point
- 触发交互
- 根据 UI 交互情况 延时 setTimeout (规避惰加载组件点不到的情况)继续 sendEvent 之类的交互
- 最后调用截图 api 发送操作结果到远端用于人工(或机器)审核 UI 结果是否正常。