如何理解皮尔逊相关系数(Pearson Correlation Coefficient)?
35 个回答

提供一个机器学习方向的解释。先上结论:在数据标准化( \mu=0,\sigma=1 )后,Pearson相关性系数、Cosine相似度、欧式距离的平方可认为是等价的。换句话说,如果你的数据符合正态分布或者经过了标准化处理,那么这三种度量方法输出等价,不必纠结使用哪一种。对于标准化后的数据求欧氏距离平方并经过简单的线性变化,其实就是Pearson系数 [1],详见证明2。
我个人觉得比较容易理解的步骤是:我们一般用欧式距离(向量间的距离)来衡量向量的相似度,但欧式距离无法考虑不同变量间取值的差异。举个例子,变量a取值范围是0至1,而变量b的取值范围是0至10000,计算欧式距离时变量b上微小的差异就会决定运算结果。而Pearson相关性系数可以看出是升级版的欧氏距离平方,因为它提供了对于变量取值范围不同的处理步骤。因此对不同变量间的取值范围没有要求(unit free),最后得到的相关性所衡量的是趋势,而不同变量量纲上差别在计算过程中去掉了,等价于z-score标准化。
而未经升级的欧式距离以及cosine相似度,对变量的取值范围是敏感的,在使用前需要进行适当的处理。我个人的经验是,在低维度可以优先使用标准化后的欧式距离或者其他距离度量,在高维度时Pearson相关系数更加适合。不过说到底,这几个衡量标准差别不大,很多时候的输出结果是非常相似的。
回答的结构如下:1. 定义一些基础概念和公式 2. 证明这三种测量方法间的等价性 3. 通过实验结果验证等价性(实验代码需要Python 3,工具库numpy,scipy和sklearn)。
假设我们有两个向量 X=[X_1, ...X_n] 和 Y=[Y_1, ...Y_n] ,长度均为 n 。
欧氏距离(Euclidean Distance)是常见的相似性度量方法,可求两个向量间的距离,取值范围为0至正无穷。显然,如果两个向量间的距离较小,那么向量也肯定更为相似。此处需要注意的一点是,欧氏距离计算默认对于每一个维度给予相同的权重,因此如果不同维度的取值范围差别很大,那么结果很容易被某个维度所决定。解决方法除了对数据进行处理以外,还可以使用加权欧氏距离,不同维度使用不同的权重。本文中我们使用的是欧氏距离的平方。
- 公式1: d(X,Y)=\sum_{i=1}^{n}{(X_n-Y_n)^2}
Pearson相关性系数(Pearson Correlation)是衡量向量相似度的一种方法。输出范围为-1到+1, 0代表无相关性,负值为负相关,正值为正相关。
- 公式2: \rho(X,Y)=\frac{E[(X-\mu_{X})(Y-\mu_{Y})]}{\sigma_X\sigma_Y} =\frac{E[(X-\mu_{X})(Y-\mu_{Y})]}{\sqrt{\sum_{i=1}^{n}{(X_i-\mu_X)^2}}\sqrt{\sum_{i=1}^{n}{(Y_i-\mu_Y)^2}}}
Cosine相似度也是一种相似性度量,输出范围和Pearson相关性系数一致,含义也相似。
- 公式3: c(X,Y)=\frac{X\cdot Y}{\left| X \right|\left| Y \right|} =\frac{\sum_{i=1}^{n}{X_iY_i}}{\sqrt{\sum_{i=1}^{n}{X_i^2}}\sqrt{\sum_{i=1}^{n}{Y_i^2}}}
标准化(Standardization)是一种常见的数据缩放手段,标准化后的数据均值为0,标准差为1。
- 公式4: z(X) = \frac{X_i-\mu _X}{\sigma_X}
平方和(Summed Square)与样本方差(Sample Variance)之间的关系:
- 公式5: \sigma_X=\sqrt{\frac{\sum_{i=1}^{n}{(X_i-\mu_X)^2}}{n-1}}
- 公式6:由公式5可得 (n-1)\sigma_X^2 = \sum_{i=1}^{n}{(X_i-\mu_X)^2}
证明1: Pearson相关性系数与Cosine Similarity在数据被标准化后等价
观察公式2和公式3,易发现如果将公式3中的X和Y代入公式4,可得
c(X,Y)=\frac{\sum_{i=1}^{n}{X_iY_i}}{\sqrt{\sum_{i=1}^{n}{X_i^2}}\sqrt{\sum_{i=1}^{n}{Y_i^2}}} =\frac{z(X)\cdot z(Y)}{\left| z(X) \right|\left| z(Y) \right|} 因为此时 \mu=0,\sigma=1 ,所以经过化简后会发现公式2和3等价。为了节省空间,过程略去,可参考其他答主的回答。
证明2:Pearson相关性系数和欧式距离方在标准化数据下等价
为了简化公式,此处的 X,Y 我们默认已经经过了标准化处理,因此均值为0,标准差为1。在这种情况下我们可以利用了公式5和6化简 \sum_{i=1}^{n}{X_i^2} 和 \sum_{i=1}^{n}{Y_i^2},得到下式:\sum_{i=1}^{n}{X_i^2}=\sum_{i=1}^{n}{(X_i-0)^2}=\sum_{i=1}^{n}{(X_i-\mu_X)^2}=(n-1)\sigma_X^2=n-1 ,当 n 取值很大时 n-1\rightarrow n ,所以我们可得到 \sum_{i=1}^{t}{X_i^2}=\sum_{i=1}^{t}{Y_i^2}= n ,这个结论马上会用到。
让我们开始展开欧氏距离方(第二步到第三步使用了我们上边的推导):
\begin{equation} \begin{split} d(X,Y)&=\sum_{i=1}^{n}{(X_n-Y_n)^2} \\ &=\sum_{i=1}^{n}{X_i}^2 - 2 \sum_{i=1}^{n}{X_iY_i}+\sum_{i=1}^{n}{Y_i}^2 \\ &= 2n - 2 \sum_{i=1}^{n}{X_iY_i}\\ &=2n(1-\sum_{i=1}^{n}{X_iY_i})\\ &=2n(1-\frac{\sum_{i=1}^{n}{(X_i-0)(Y_i-0)}}{1\cdot1})\\ &=2n(1-\frac{E[(X-\mu_X)(Y-\mu_Y)]}{\sigma_X\sigma_Y}\\ &= 2n(1-\rho(X,Y)) \end{split} \end{equation}
于是我们得到了结论 d(X,Y) =2n(1-\rho(X,Y)) ,此处的n是向量的长度,是常数,因此我们依然可以认为是等价的。
划重点:欧氏距离的平方 = 2 * 常数n (也就是向量的长度)* (1-Pearson相关系数)
证明3:Cosine相似度和欧氏距离方等价
通过证明1和2,易得证明3,略去。
实验证明:
我随机生成了三个向量(长度为100),并分别计算两两之间的Pearson相关性系数,Cosine相似度和欧式距离方:
- 原始数据,没有任何处理
- 经过了标准化(公式4)后的结果
结果如下图,可见标准化后三者等价。此处需要注意因为Pearson可能是负数,因此我用1-Pearson,之后结果就会是非负数并处于区间 [0,2] ,这样就可以和欧氏距离这个非负进行对比。

import numpy as np
from scipy.stats import pearsonr
from scipy.spatial.distance import euclidean
from scipy.spatial.distance import cosine
from sklearn.preprocessing import StandardScaler
# 设定向量长度,均为100
n = 100
x1 = np.random.random_integers(0, 10, (n,1))
x2 = np.random.random_integers(0, 10, (n,1))
x3 = np.random.random_integers(0, 10, (n,1))
p12 = 1 - pearsonr(x1, x2)[0][0]
p13 = 1 - pearsonr(x1, x3)[0][0]
p23 = 1 - pearsonr(x2, x3)[0][0]
d12 = (euclidean(x1, x2)**2) / (2*n)
d13 = (euclidean(x1, x3)**2) / (2*n)
d23 = (euclidean(x2, x3)**2) / (2*n)
c12 = cosine(x1, x2)
c13 = cosine(x1, x3)
c23 = cosine(x2, x3)
print('\n原始数据,没有标准化\n')
print(' x1&x2 x2&x3 x1&x3')
print('pearson: ', np.round(p12, decimals=4), np.round(p13, decimals=4),
np.round(p23, decimals=4))
print('cos: ', np.round(c12, decimals=4), np.round(c13, decimals=4),
np.round(c23, decimals=4))
print('euclidean sq', np.round(d12, decimals=4), np.round(d13, decimals=4),
np.round(d23, decimals=4))
# 标准化后的数据
x1_n = StandardScaler().fit_transform(x1)
x2_n = StandardScaler().fit_transform(x2)
x3_n = StandardScaler().fit_transform(x3)
p12_n = 1 - pearsonr(x1_n, x2_n)[0][0]
p13_n = 1 - pearsonr(x1_n, x3_n)[0][0]
p23_n = 1 - pearsonr(x2_n, x3_n)[0][0]
d12_n = (euclidean(x1_n, x2_n)**2) / (2*n)
d13_n = (euclidean(x1_n, x3_n)**2) / (2*n)
d23_n = (euclidean(x2_n, x3_n)**2) / (2*n)
c12_n = cosine(x1_n, x2_n)
c13_n = cosine(x1_n, x3_n)
c23_n = cosine(x2_n, x3_n)
print('\n标准化后的数据: 均值=0,标准差=1\n')
print(' x1&x2 x2&x3 x1&x3')
print('pearson: ', np.round(p12_n, decimals=4), np.round(p13_n, decimals=4),
np.round(p23_n, decimals=4))
print('cos: ', np.round(c12_n, decimals=4), np.round(c13_n, decimals=4),
np.round(c23_n, decimals=4))
print('euclidean sq', np.round(d12_n, decimals=4), np.round(d13_n, decimals=4),
np.round(d23_n, decimals=4))
[1] Berthold, M.R. and Höppner, F., 2016. On clustering time series using euclidean distance and pearson correlation. arXiv preprint arXiv:1601.02213.

要理解Pearson相关系数,首先要理解协方差(Covariance),协方差是一个反映两个随机变量相关程度的指标,如果一个变量跟随着另一个变量同时变大或者变小,那么这两个变量的协方差就是正值,反之相反,公式如下:
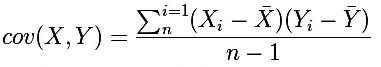
Pearson相关系数公式如下:
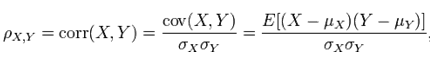

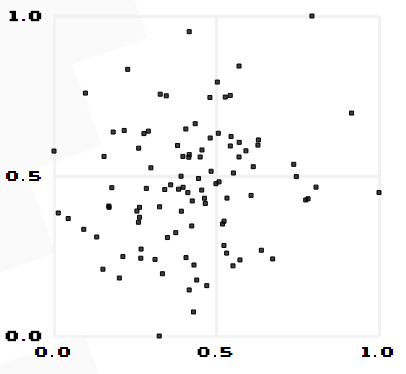
由公式可知,Pearson相关系数是用协方差除以两个变量的标准差得到的,虽然协方差能反映两个随机变量的相关程度(协方差大于0的时候表示两者正相关,小于0的时候表示两者负相关),但是协方差值的大小并不能很好地度量两个随机变量的关联程度,例如,现在二维空间中分布着一些数据,我们想知道数据点坐标X轴和Y轴的相关程度,如果X与Y的相关程度较小但是数据分布的比较离散,这样会导致求出的协方差值较大,用这个值来度量相关程度是不合理的,如下图:
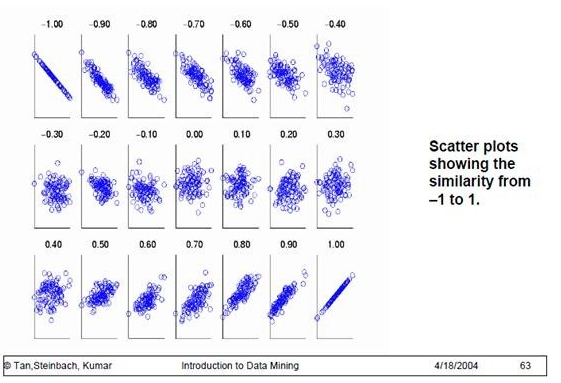
为了更好的度量两个随机变量的相关程度,引入了Pearson相关系数,其在协方差的基础上除以了两个随机变量的标准差,容易得出,pearson是一个介于-1和1之间的值,当两个变量的线性关系增强时,相关系数趋于1或-1;当一个变量增大,另一个变量也增大时,表明它们之间是正相关的,相关系数大于0;如果一个变量增大,另一个变量却减小,表明它们之间是负相关的,相关系数小于0;如果相关系数等于0,表明它们之间不存在线性相关关系。《数据挖掘导论》给出了一个很好的图来说明: