三维重建 3D reconstruction 有哪些实用算法?
48 个回答


在这个问题下,竟然没有人说大名鼎鼎的KinectFusion以及他后面的一系列工作?KinectFusion单篇论文引用都已经超过3000次了,不应该啊!
如果只想看现阶段效果最好的三维重建算法,请拉到文章最后(如有更好的算法,还请告知)。
一、KinectFusion
帝国理工的Newcombe等人在2011年提出的KinectFusion,可在不需要RGB图而只用深度图的情况下就能实时地建立三维模型。KinectFusion算法首次实现了基于廉价消费类相机的实时刚体重建,在当时是非常有影响力的工作,它极大的推动了实时稠密三维重建的商业化进程。


在他们的论文中没有开源代码,最初的代码是由PCL团队实现的:kinectfusion-open-source
KinectFusion的重建效果可以看这个视频:
 KinectFusion重建效果https://www.zhihu.com/video/1184501699569471488
KinectFusion重建效果https://www.zhihu.com/video/1184501699569471488KinectFusion之后,陆续出现了Kintinuous,ElasticFusion,ElasticReconstruction,DynamicFusion,InfiniTAM,BundleFusion等非常优秀的工作。其中2017年斯坦福大学提出的BundleFusion算法,据说是目前基于RGB-D相机进行稠密三维重建效果最好的方法。
二、Kintinuous和ElasticFusion
这两个工作都是同一个人做出来的,这个人就是Thomas Whelan。这两个工作应该算KinectFusion之后影响力比较大的。
Kintinuous GitHub代码:mp3guy/Kintinuous
ElasticFusion GitHub代码:mp3guy/ElasticFusion
Kintinuous2.0重建效果:


ElasticFusion 重建效果:


三、ElasticReconstruction
项目官网:http://qianyi.info/scene.html
GitHub代码:qianyizh/ElasticReconstruction
重建效果:


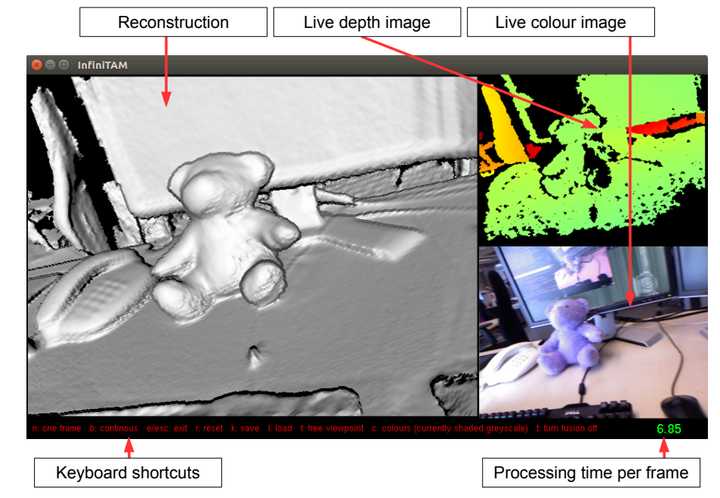
四、InfiniTAM
InfiniTAM提供Linux,iOS,Android平台版本,CPU可以实时重建。
官网:InfiniTAM v3
GitHub代码:victorprad/InfiniTAM
重建效果:

五、DynamicFusion
代码:https://github.com/mihaibujanca/dynamicfusion
重建效果:


六、BundleFusion
据说是现在重建效果最好的工作!
官网:BundleFusion
论文:https://arxiv.org/pdf/1604.01093.pdf
算法解读:计算机视觉方向简介 | 深度相机室内实时稠密三维重建
重建效果:
 BundleFusion:最好的三维重建https://www.zhihu.com/video/1184509281717673984
BundleFusion:最好的三维重建https://www.zhihu.com/video/1184509281717673984最近国防科大张博士也发表了一篇稠密三维重建的文章 (ROSEFusion)。仅依靠深度图作为输入,利用随机优化实现了快速相机下的稠密重建。代码已经开源https://github.com/jzhzhang/ROSEFusion




ROSEFusion 能够在仅考虑深度图作为输入的条件下,利用随机优化求解相机位姿,实现了在快速相机移动下的室内场景稠密重建。同时该工作仅依赖深度信息,因此也可以在无光照,和变化光照的条件下使用。 该工作的主要特点是:(a) 利用深度图和TSDF相容性作为代价函数,不需要提取特征点,仅依赖于深度图;(b) 提出了Particle Swarm Template(PST),利用PST可以高效的对相机位姿空间进行采样,并利用随机优化求解出相机的位姿。
倾情整理,建议收藏。
如果能点赞就更好。

2021年10月25日更新
之前有许多小伙伴说想找stf的代码,但是评论中@bliss博士提供的网址一直404,说是创业去了。但是最近我发现Adrien Bartoli大牛更新了个人主页,开源了许多相关工作的代码,甚至有近几年的工作。有兴趣的小伙伴可以研究下。
代码主页: http://igt.ip.uca.fr/~ab/code_and_datasets/index.php
------------------------------------------------这是分割线--------------------------------------------------
收藏这个问题很久,楼上各位大佬已经总结的很好,大部分回答介绍了对刚体的三维重建工作,但对非刚体三维重建的工作介绍还比较少。刚好读研时做过这方面的调研和学习,来做一点点补充吧。
高赞 @曹力科 博士的回答介绍了基于RGBD的实时三维重建工作,各种XXXFusion效果很是惊艳,而且可以实时重建出动态物体的三维模型。但是也有个问题,要是RGBD相机我也觉得贵怎么办,我就想用普通的RGB相机去进行动态三维,还想只用一个RGB相机去完成重建。
学术界那帮大佬也这么想,想用最最最简单的设备去解决某个复杂的问题,即采用单目的RGB相机去进行动态三维重建。大道至简嘛,不然怎么体现出大佬的水平,手动狗头。
同时问题也来了,单目RGB相机在投影时已经失去了深度信息,如何恢复深度和重建呢?有这么几类方案。
一、NRSfM(NonRigid Structure from Motion)
Bregler等人[1]首先提出了NRSfM的思想,他们提出将目标物体在每一帧上的三维变形形状表示为K个形状基的线性加权组合,然后通过分解刚性系数矩阵来得到随时间序列变化的形状基、组合系数和摄像机运动参数。基于低秩形状的约束是一个强大的约束,但是它的求解是一个病态不定问题。
这类重建方案我不是很熟,只介绍个做的比较好的。
Ravi Garg等人CVPR2013的工作,论文地址:
Dense Variational Reconstruction of Non-Rigid Surfaces from Monocular Video∗
重建可以得到稠密的结果,效果还是很不错的,就是需要得到完整的视频后才能重建。
重建结果:


二、SfT(Shape from Template)
另外一种方法是SfT。这种重建方法需要预先得到目标物体在刚性状态下的三维模型来作为模板,后面模型去追踪单目视频里目标物体的变化,得到每一帧图像对应的形变三维模型。这种方法具有实时重建的可能。
重建的时候一般使用网格来表示三维模型,大佬们发现物体在发生形变时对应的网格模型是存在着约束的:等距约束(相邻网格顶点之间的距离在变形过程中保持不变)、平滑先验(相邻顶点的变形应该相似)和尽可能的刚性先验(变形可以用局部刚体运动近似)。打个比方,吹气球气球变大的过程中,气球上的某个点和它附件的点变化的趋势是相似的,但是这些点变大时又保持着最开始的拓扑结构。
1.Adrien Bartoli团队的工作
SfT的理论由Adrien Bartoli等人总结提出,对平面进行了稀疏重建。论文地址:Bartoli_etal_SfT
Bartoli主页:http://igt.ip.uca.fr/~ab/index.html
重建结果:


后面他们团队拓展了这个方法,对稠密完整的物体进行了重建,而且给出了一个Demo。
论文地址:http://igt.ip.uca.fr/~ab/Publications/Collins_Bartoli_ISMAR15.pdf
论文中说好的会公开源码,但是我没找到。
重建结果:

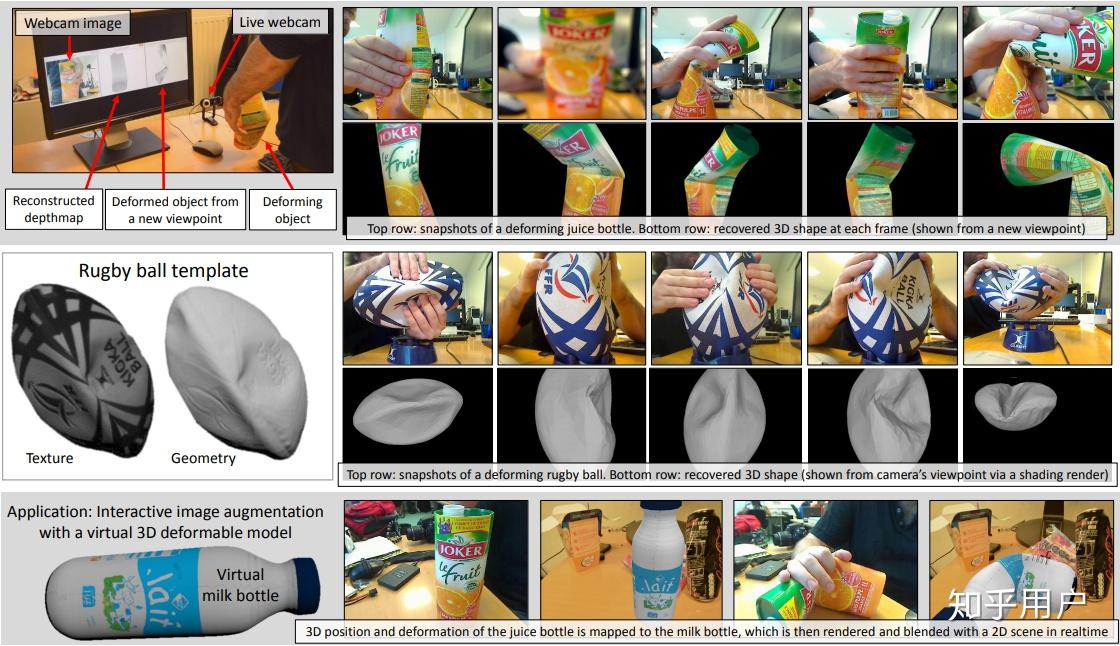
演示视频:
他们组后续还有一些相关工作,都是对这个方法的改进:http://igt.ip.uca.fr/~ab/Publications/Parashar_etal_ICCV15.pdf
此外这个组在arxiv上挂了一篇用深度学习方法做的SfT,但是现在还没正式发表,实验结果并不能重建得到完整的动态三维模型,只针物体的一个面完成了重建。
https://arxiv.org/pdf/1811.07791.pdf
2.Lourdes Agapito团队的工作
这方面的工作主要由@余瑞 博士做的,并且开源了源码。论文地址:http://www0.cs.ucl.ac.uk/staff/R.Yu/direct_nrsfm/direct_nrsfm.pdf
项目主页:http://www0.cs.ucl.ac.uk/staff/R.Yu/direct_nrsfm/direct_nrsfm.html
代码:https://github.com/cvfish/PangaeaTracking
重建结果:


演示视频:
一年后在这个基础上又做出了改进,把shape-from-shading的方法加入到整个系统中,提高了重建的质量和精度。可以发现下图重建的结果更好了,多了很多细节。
论文地址:http://www0.cs.ucl.ac.uk/staff/Qi.Liu/bmvc16/better_together.pdf
项目主页:http://www0.cs.ucl.ac.uk/staff/Qi.Liu/bmvc16/better_together.html
代码:https://github.com/qilon/PangaeaTracking
重建结果


3.马普所团队的工作
马普所的Marc Habermann等人把@余瑞 博士的工作改进应用到了人体动态三维重建方面。
论文地址:https://gvv.mpi-inf.mpg.de/projects/LiveCap/data/livecap.pdf
项目地址:https://gvv.mpi-inf.mpg.de/projects/LiveCap/
重建结果:


三、基于模型的方法 (Model-based methods)
这一类方法主要代表是HMR等,主要针对于人体和动物,作者建立了两个模型库SMPL和SMAL,然后把人或动物的姿态给模型参数化了。这几个项目用到深度学习的方法。
作者Angjoo Kanazawa主页:https://people.eecs.berkeley.edu/~kanazawa/
Github:https://github.com/akanazawa
演示视频:
 https://www.zhihu.com/video/1247867048929185792
https://www.zhihu.com/video/1247867048929185792 https://www.zhihu.com/video/1247867124434636800
https://www.zhihu.com/video/1247867124434636800四、其他
除此之外还有一些对于人脸的重建,如Face2Face等。也是输入单目视频得到重建结果,这块我没去了解过,就不多介绍了。
做单目动态三维重建的团队还有Mathieu Salzmann等人和 @戴玉超 老师在的团队,但是成果都是偏向稀疏的重建,而且近几年没有看到新的成果,感兴趣的小伙伴可以去找找相关资料。
国内西安交通大学的Wang Xuan博士在这个方向也做了部分工作,他在Mathieu Salzmann组做过访问学生。论文链接:
戴老师的工作,论文链接:
这篇回答主要介绍了几个稠密的重建方案,采用的方法也比较传统,大多是基于优化的方式进行的重建,目前深度学习的方法应用在这个领域的方案还比较少,没看到什么令人惊艳的成果。
由于水平有限,这篇回答仅抛砖引玉一下。肯定存在着很多纰漏和错误,请小伙伴们多多补充和指正。
五、引用
[1]Recovering Non-Rigid 3D Shape from Image Streams.Christoph Bregler, Aaron Hertzmann and Henning Biermann.Proc. IEEE CVPR 2000