能否对卷积神经网络工作原理做一个直观的解释?
125 个回答

近日,Dishashree Gupta 在 Analyticsvidhya 上发表了一篇题为《Architecture of Convolutional Neural Networks (CNNs) demystified》的文章,对用于图像识别和分类的卷积神经网络架构作了深度揭秘;作者在文中还作了通盘演示,期望对 CNN 的工作机制有一个深入的剖析。机器之心对本文进行了编译,原文链接在此,希望对你有帮助。
机器视角:长文揭秘图像处理和卷积神经网络架构
引言
先坦白地说,有一段时间我无法真正理解深度学习。我查看相关研究论文和文章,感觉深度学习异常复杂。我尝试去理解神经网络及其变体,但依然感到困难。
接着有一天,我决定一步一步,从基础开始。我把技术操作的步骤分解开来,并手动执行这些步骤(和计算),直到我理解它们如何工作。这相当费时,且令人紧张,但是结果非凡。
现在,我不仅对深度学习有了全面的理解,还在此基础上有了好想法,因为我的基础很扎实。随意地应用神经网络是一回事,理解它是什么以及背后的发生机制是另外一回事。
今天,我将与你共享我的心得,展示我如何上手卷积神经网络并最终弄明白了它。我将做一个通盘的展示,从而使你对 CNN 的工作机制有一个深入的了解。
在本文中,我将会讨论 CNN 背后的架构,其设计初衷在于解决图像识别和分类问题。同时我也会假设你对神经网络已经有了初步了解。
目录
1.机器如何看图?
2.如何帮助神经网络识别图像?
3.定义卷积神经网络
- 卷积层
- 池化层
- 输出层
4.小结
5.使用 CNN 分类图像
1. 机器如何看图?
人类大脑是一非常强大的机器,每秒内能看(捕捉)多张图,并在意识不到的情况下就完成了对这些图的处理。但机器并非如此。机器处理图像的第一步是理解,理解如何表达一张图像,进而读取图片。
简单来说,每个图像都是一系列特定排序的图点(像素)。如果你改变像素的顺序或颜色,图像也随之改变。举个例子,存储并读取一张上面写着数字 4 的图像。
基本上,机器会把图像打碎成像素矩阵,存储每个表示位置像素的颜色码。在下图的表示中,数值 1 是白色,256 是最深的绿色(为了简化,我们示例限制到了一种颜色)。

一旦你以这种格式存储完图像信息,下一步就是让神经网络理解这种排序与模式。
2. 如何帮助神经网络识别图像?
表征像素的数值是以特定的方式排序的。

假设我们尝试使用全连接网络识别图像,该如何做?
全连接网络可以通过平化它,把图像当作一个数组,并把像素值当作预测图像中数值的特征。明确地说,让网络理解理解下面图中发生了什么,非常的艰难。


即使人类也很难理解上图中表达的含义是数字 4。我们完全丢失了像素的空间排列。
我们能做什么呢?可以尝试从原图像中提取特征,从而保留空间排列。
案例 1
这里我们使用一个权重乘以初始像素值。


现在裸眼识别出这是「4」就变得更简单了。但把它交给全连接网络之前,还需要平整化(flatten) 它,要让我们能够保留图像的空间排列。


案例 2
现在我们可以看到,把图像平整化完全破坏了它的排列。我们需要想出一种方式在没有平整化的情况下把图片馈送给网络,并且还要保留空间排列特征,也就是需要馈送像素值的 2D/3D 排列。
我们可以尝试一次采用图像的两个像素值,而非一个。这能给网络很好的洞见,观察邻近像素的特征。既然一次采用两个像素,那也就需要一次采用两个权重值了
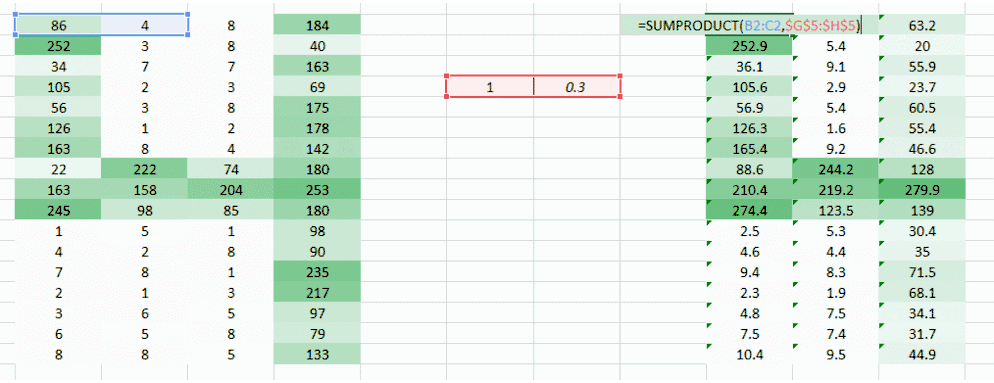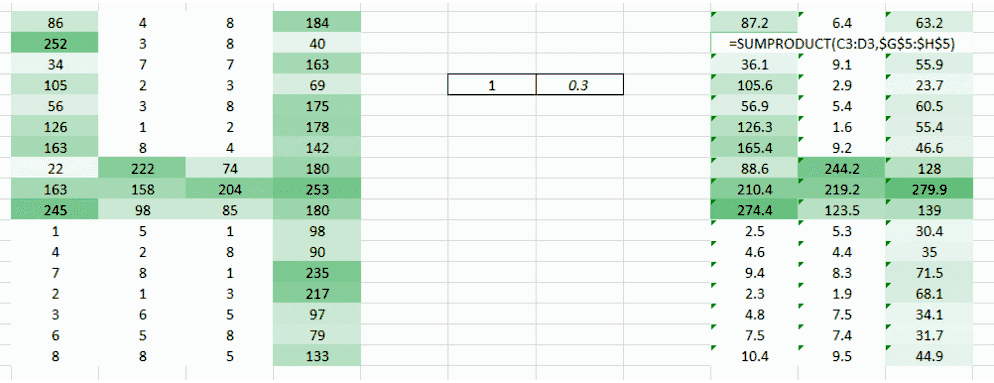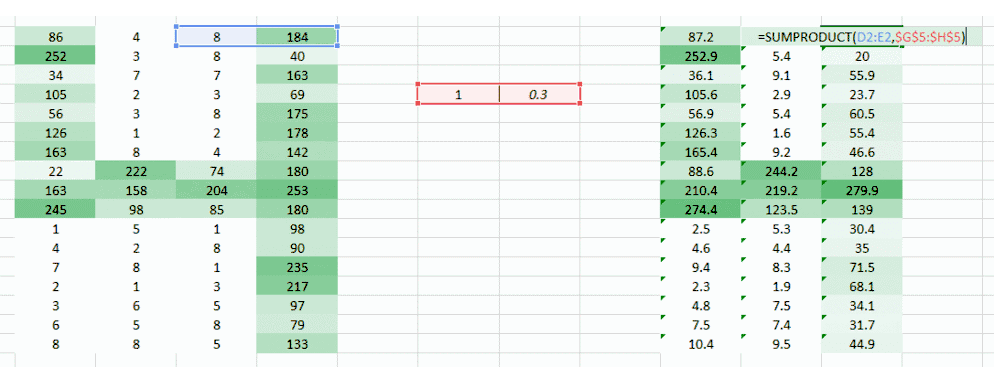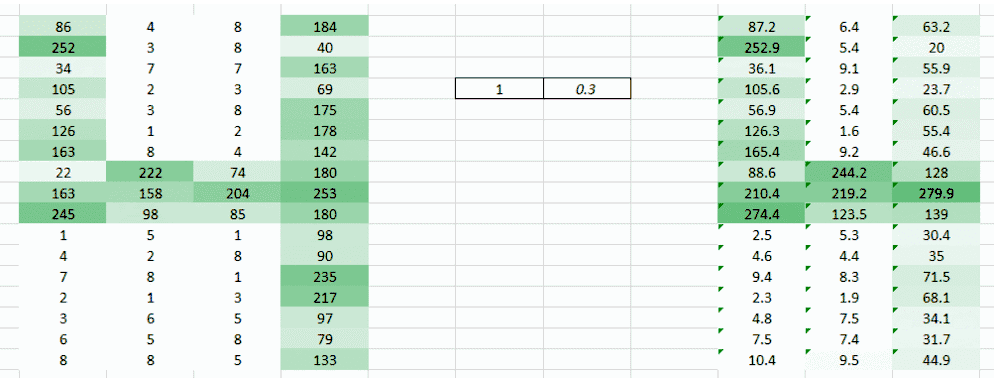

希望你能注意到图像从之前的 4 列数值变成了 3 列。因为我们现在一次移用两个像素(在每次移动中像素被共享),图像变的更小了。虽然图像变小了,我们仍能在很大程度上理解这是「4」。而且,要意识到的一个重点是,我们采用的是两个连贯的水平像素,因此只会考虑水平的排列。
这是我们从图像中提取特征的一种方式。我们可以看到左边和中间部分,但右边部分看起来不那么清楚。主要是因为两个问题:
1. 图片角落左边和右边是权重相乘一次得到的。
2. 左边仍旧保留,因为权重值高;右边因为略低的权重,有些丢失。
现在我们有两个问题,需要两个解决方案。
案例 3
遇到的问题是图像左右两角只被权重通过一次。我们需要做的是让网络像考虑其他像素一样考虑角落。我们有一个简单的方法解决这一问题:把零放在权重运动的两边。
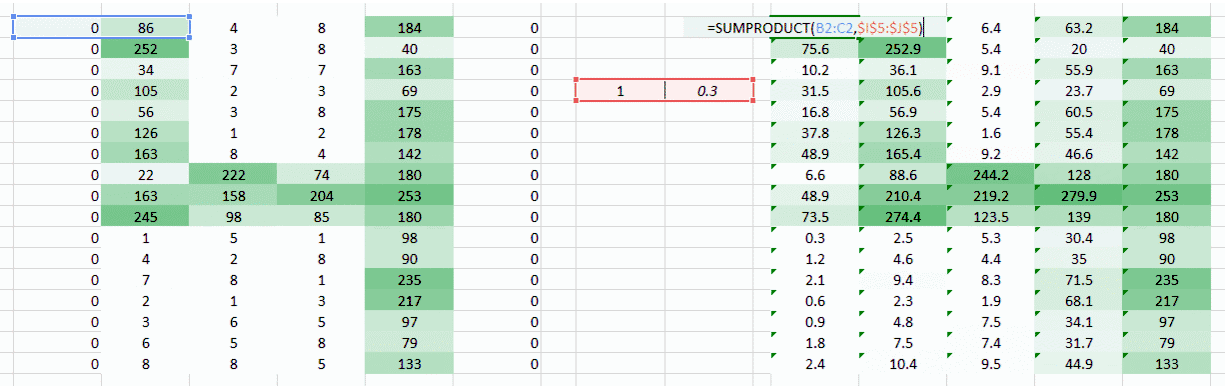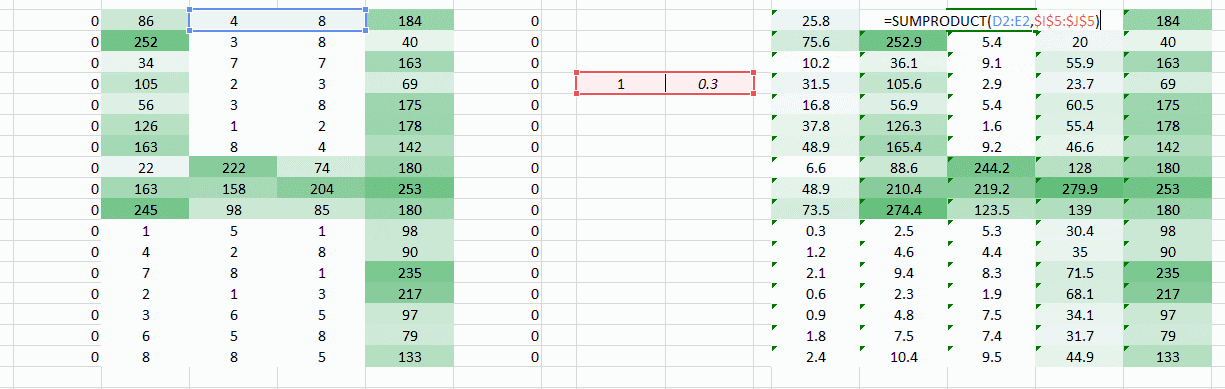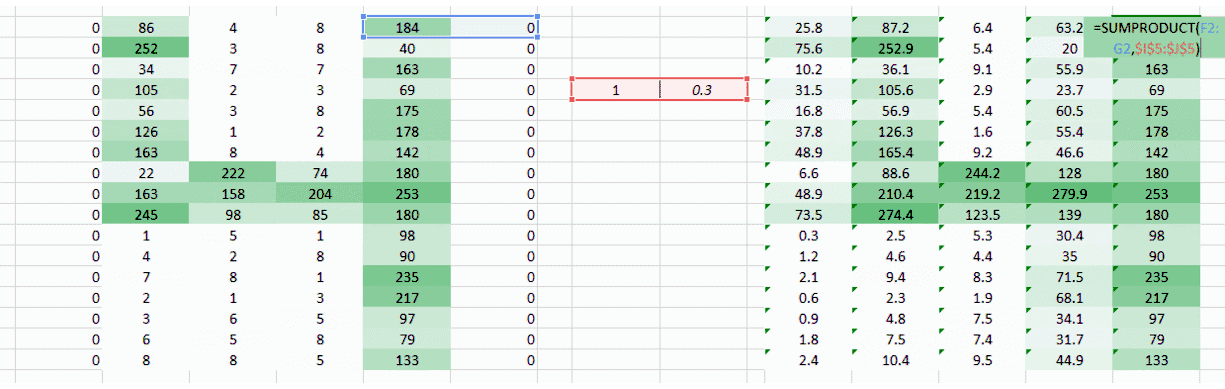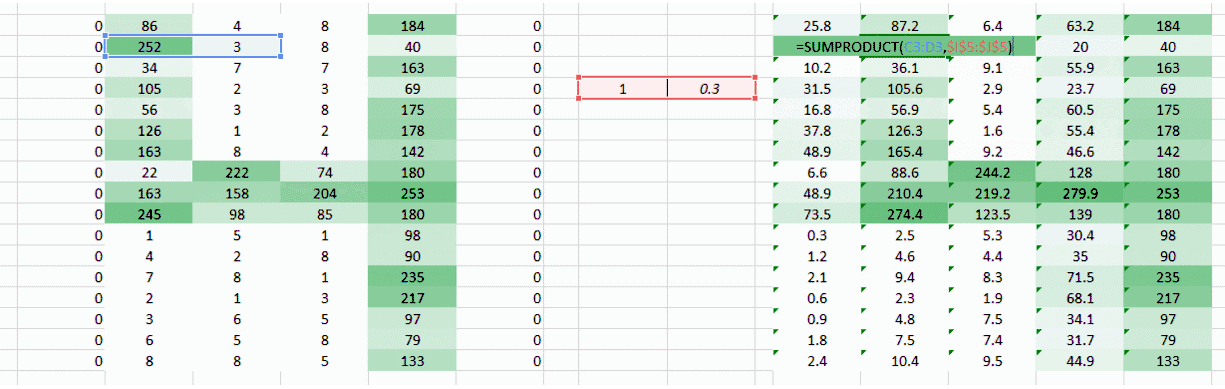

你可以看到通过添加零,来自角落的信息被再训练。图像也变得更大。这可被用于我们不想要缩小图像的情况下。
案例 4
这里我们试图解决的问题是右侧角落更小的权重值正在降低像素值,因此使其难以被我们识别。我们所能做的是采取多个权重值并将其结合起来。
(1,0.3) 的权重值给了我们一个输出表格

同时表格 (0.1,5) 的权重值也将给我们一个输出表格。

两张图像的结合版本将会给我们一个清晰的图片。因此,我们所做的是简单地使用多个权重而不是一个,从而再训练图像的更多信息。最终结果将是上述两张图像的一个结合版本。
案例 5
我们到现在通过使用权重,试图把水平像素(horizontal pixel)结合起来。但是大多数情况下我们需要在水平和垂直方向上保持空间布局。我们采取 2D 矩阵权重,把像素在水平和垂直方向上结合起来。同样,记住已经有了水平和垂直方向的权重运动,输出会在水平和垂直方向上低一个像素。


特别感谢 Jeremy Howard 启发我创作了这些图像。
因此我们做了什么?
上面我们所做的事是试图通过使用图像的空间的安排从图像中提取特征。为了理解图像,理解像素如何安排对于一个网络极其重要。上面我们所做的也恰恰是一个卷积网络所做的。我们可以采用输入图像,定义权重矩阵,并且输入被卷积以从图像中提取特殊特征而无需损失其有关空间安排的信息。
这个方法的另一个重大好处是它可以减少图像的参数数量。正如所见,卷积图像相比于原始图像有更少的像素。
3.定义一个卷积神经网络
我们需要三个基本的元素来定义一个基本的卷积网络
1. 卷积层
2. 池化层(可选)
3. 输出层
卷积层
在这一层中,实际所发生的就像我们在上述案例 5 中见到的一样。假设我们有一个 6*6 的图像。我们定义一个权值矩阵,用来从图像中提取一定的特征。
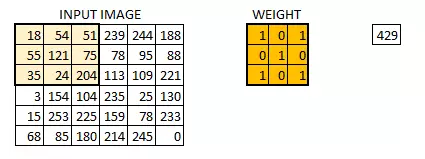

我们把权值初始化成一个 3*3 的矩阵。这个权值现在应该与图像结合,所有的像素都被覆盖至少一次,从而来产生一个卷积化的输出。上述的 429,是通过计算权值矩阵和输入图像的 3*3 高亮部分以元素方式进行的乘积的值而得到的。


现在 6*6 的图像转换成了 4*4 的图像。想象一下权值矩阵就像用来刷墙的刷子。首先在水平方向上用这个刷子进行刷墙,然后再向下移,对下一行进行水平粉刷。当权值矩阵沿着图像移动的时候,像素值再一次被使用。实际上,这样可以使参数在卷积神经网络中被共享。
下面我们以一个真实图像为例。


权值矩阵在图像里表现的像一个从原始图像矩阵中提取特定信息的过滤器。一个权值组合可能用来提取边缘(edge)信息,另一个可能是用来提取一个特定颜色,下一个就可能就是对不需要的噪点进行模糊化。
先对权值进行学习,然后损失函数可以被最小化,类似于多层感知机(MLP)。因此需要通过对参数进行学习来从原始图像中提取信息,从而来帮助网络进行正确的预测。当我们有多个卷积层的时候,初始层往往提取较多的一般特征,随着网络结构变得更深,权值矩阵提取的特征越来越复杂,并且越来越适用于眼前的问题。
步长(stride)和边界(padding)的概念
像我们在上面看到的一样,过滤器或者说权值矩阵,在整个图像范围内一次移动一个像素。我们可以把它定义成一个超参数(hyperparameter),从而来表示我们想让权值矩阵在图像内如何移动。如果权值矩阵一次移动一个像素,我们称其步长为 1。下面我们看一下步长为 2 时的情况。


你可以看见当我们增加步长值的时候,图像的规格持续变小。在输入图像四周填充 0 边界可以解决这个问题。我们也可以在高步长值的情况下在图像四周填加不只一层的 0 边界。

我们可以看见在我们给图像填加一层 0 边界后,图像的原始形状是如何被保持的。由于输出图像和输入图像是大小相同的,所以这被称为 same padding。

这就是 same padding(意味着我们仅考虑输入图像的有效像素)。中间的 4*4 像素是相同的。这里我们已经利用边界保留了更多信息,并且也已经保留了图像的原大小。
多过滤与激活图
需要记住的是权值的纵深维度(depth dimension)和输入图像的纵深维度是相同的。权值会延伸到输入图像的整个深度。因此,和一个单一权值矩阵进行卷积会产生一个单一纵深维度的卷积化输出。大多数情况下都不使用单一过滤器(权值矩阵),而是应用维度相同的多个过滤器。
每一个过滤器的输出被堆叠在一起,形成卷积图像的纵深维度。假设我们有一个 32*32*3 的输入。我们使用 5*5*3,带有 valid padding 的 10 个过滤器。输出的维度将会是 28*28*10。
如下图所示:


激活图是卷积层的输出。
池化层
有时图像太大,我们需要减少训练参数的数量,它被要求在随后的卷积层之间周期性地引进池化层。池化的唯一目的是减少图像的空间大小。池化在每一个纵深维度上独自完成,因此图像的纵深保持不变。池化层的最常见形式是最大池化。
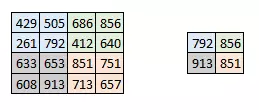
在这里,我们把步幅定为 2,池化尺寸也为 2。最大化执行也应用在每个卷机输出的深度尺寸中。正如你所看到的,最大池化操作后,4*4 卷积的输出变成了 2*2。
让我们看看最大池化在真实图片中的效果如何。


正如你看到的,我们卷积了图像,并最大池化了它。最大池化图像仍然保留了汽车在街上的信息。如果你仔细观察的话,你会发现图像的尺寸已经减半。这可以很大程度上减少参数。
同样,其他形式的池化也可以在系统中应用,如平均池化和 L2 规范池化。
输出维度
理解每个卷积层输入和输出的尺寸可能会有点难度。以下三点或许可以让你了解输出尺寸的问题。有三个超参数可以控制输出卷的大小。
1. 过滤器数量-输出卷的深度与过滤器的数量成正比。请记住该如何堆叠每个过滤器的输出以形成激活映射。激活图的深度等于过滤器的数量。
2. 步幅(Stride)-如果步幅是 1,那么我们处理图片的精细度就进入单像素级别了。更高的步幅意味着同时处理更多的像素,从而产生较小的输出量。
3. 零填充(zero padding)-这有助于我们保留输入图像的尺寸。如果添加了单零填充,则单步幅过滤器的运动会保持在原图尺寸。
我们可以应用一个简单的公式来计算输出尺寸。输出图像的空间尺寸可以计算为([W-F + 2P] / S)+1。在这里,W 是输入尺寸,F 是过滤器的尺寸,P 是填充数量,S 是步幅数字。假如我们有一张 32*32*3 的输入图像,我们使用 10 个尺寸为 3*3*3 的过滤器,单步幅和零填充。
那么 W=32,F=3,P=0,S=1。输出深度等于应用的滤波器的数量,即 10,输出尺寸大小为 ([32-3+0]/1)+1 = 30。因此输出尺寸是 30*30*10。
输出层
在多层卷积和填充后,我们需要以类的形式输出。卷积和池化层只会提取特征,并减少原始图像带来的参数。然而,为了生成最终的输出,我们需要应用全连接层来生成一个等于我们需要的类的数量的输出。仅仅依靠卷积层是难以达到这个要求的。卷积层可以生成 3D 激活图,而我们只需要图像是否属于一个特定的类这样的内容。输出层具有类似分类交叉熵的损失函数,用于计算预测误差。一旦前向传播完成,反向传播就会开始更新权重与偏差,以减少误差和损失。
4. 小结
正如你所看到的,CNN 由不同的卷积层和池化层组成。让我们看看整个网络是什么样子:


- 我们将输入图像传递到第一个卷积层中,卷积后以激活图形式输出。图片在卷积层中过滤后的特征会被输出,并传递下去。
- 每个过滤器都会给出不同的特征,以帮助进行正确的类预测。因为我们需要保证图像大小的一致,所以我们使用同样的填充(零填充),否则填充会被使用,因为它可以帮助减少特征的数量。
- 随后加入池化层进一步减少参数的数量。
- 在预测最终提出前,数据会经过多个卷积和池化层的处理。卷积层会帮助提取特征,越深的卷积神经网络会提取越具体的特征,越浅的网络提取越浅显的特征。
- 如前所述,CNN 中的输出层是全连接层,其中来自其他层的输入在这里被平化和发送,以便将输出转换为网络所需的参数。
- 随后输出层会产生输出,这些信息会互相比较排除错误。损失函数是全连接输出层计算的均方根损失。随后我们会计算梯度错误。
- 错误会进行反向传播,以不断改进过滤器(权重)和偏差值。
- 一个训练周期由单次正向和反向传递完成。
5. 在 KERAS 中使用 CNN 对图像进行分类
让我们尝试一下,输入猫和狗的图片,让计算机识别它们。这是图像识别和分类的经典问题,机器在这里需要做的是看到图像,并理解猫与狗的不同外形特征。这些特征可以是外形轮廓,也可以是猫的胡须之类,卷积层会攫取这些特征。让我们把数据集拿来试验一下吧。
以下这些图片均来自数据集。


我们首先需要调整这些图像的大小,让它们形状相同。这是处理图像之前通常需要做的,因为在拍照时,让照下的图像都大小相同几乎不可能。
为了简化理解,我们在这里只用一个卷积层和一个池化层。注意:在 CNN 的应用阶段,这种简单的情况是不会发生的。
#import various packagesimport osimport numpy as npimport pandas as pdimport scipyimport sklearnimport kerasfrom keras.models import Sequentialimport cv2from skimage import io
%matplotlib inline
#Defining the File Path
cat=os.listdir("/mnt/hdd/datasets/dogs_cats/train/cat")
dog=os.listdir("/mnt/hdd/datasets/dogs_cats/train/dog")
filepath="/mnt/hdd/datasets/dogs_cats/train/cat/"filepath2="/mnt/hdd/datasets/dogs_cats/train/dog/"#Loading the Images
images=[]
label = []for i in cat:
image = scipy.misc.imread(filepath+i)
images.append(image)
label.append(0) #for cat imagesfor i in dog:
image = scipy.misc.imread(filepath2+i)
images.append(image)
label.append(1) #for dog images
#resizing all the imagesfor i in range(0,23000):
images[i]=cv2.resize(images[i],(300,300))
#converting images to arrays
images=np.array(images)
label=np.array(label)
# Defining the hyperparameters
filters=10filtersize=(5,5)
epochs =5batchsize=128input_shape=(300,300,3)
#Converting the target variable to the required sizefrom keras.utils.np_utils import to_categorical
label = to_categorical(label)
#Defining the model
model = Sequential()
model.add(keras.layers.InputLayer(input_shape=input_shape))
model.add(keras.layers.convolutional.Conv2D(filters, filtersize, strides=(1, 1), padding='valid', data_format="channels_last", activation='relu'))
model.add(keras.layers.MaxPooling2D(pool_size=(2, 2)))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(units=2, input_dim=50,activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(images, label, epochs=epochs, batch_size=batchsize,validation_split=0.3)
model.summary()在这一模型中,我只使用了单一卷积和池化层,可训练参数是 219,801。很好奇如果我在这种情况使用了 MLP 会有多少参数。通过增加更多的卷积和池化层,你可以进一步降低参数的数量。我们添加的卷积层越多,被提取的特征就会更具体和复杂。
在该模型中,我只使用了一个卷积层和池化层,可训练参数量为 219,801。如果想知道使用 MLP 在这种情况下会得到多少,你可以通过加入更多卷积和池化层来减少参数的数量。越多的卷积层意味着提取出来的特征更加具体,更加复杂。
结语
希望本文能够让你认识卷积神经网络,这篇文章没有深入 CNN 的复杂数学原理。如果希望增进了解,你可以尝试构建自己的卷积神经网络,借此来了解它运行和预测的原理。
本文首发于微信公众号:机器之心(almosthuman2014),如需转载,请私信联系,感谢。

谈点个人理解,占个坑。
按照我的理解,CNN的核心其实就是卷积核的作用,只要明白了这个问题,其余的就都是数学坑了(当然,相比较而言之后的数学坑更难)。
如果学过数字图像处理,对于卷积核的作用应该不陌生,比如你做一个最简单的方向滤波器,那就是一个二维卷积核,这个核其实就是一个模板,利用这个模板再通过卷积计算的定义就可以计算出一幅新的图像,新的图像会把这个卷积核所体现的特征突出显示出来。比如这个卷积核可以侦测水平纹理,那卷积出来的图就是原图水平纹理的图像。
现在假设要做一个图像的分类问题,比如辨别一个图像里是否有一只猫,我们可以先判断是否有猫的头,猫的尾巴,猫的身子等等,如果这些特征都具备,那么我就判定这应该是一只猫(如果用心的话你就会发现这就是CNN最后的分类层,这一部分是我们传统的神经网络的范畴)。关键在于这些特征是高级的语义特征,这种特征怎么用卷积核提取呢?
原来的卷积核都是人工事先定义好的,是经过算法设计人员精心设计的,他们发现这样或那样的设计卷积核通过卷积运算可以突出一个什么样的特征,于是就高高兴兴的拿去卷积了。但是现在我们所需要的这种特征太高级了,而且随任务的不同而不同,人工设计这样的卷积核非常困难。
于是,利用机器学习的思想,我们可以让他自己去学习出卷积核来!也就是学习出特征!
如前所述,判断是否是一只猫,只有一个特征不够,比如仅仅有猫头是不足的,因此需要多个高级语义特征的组合,所以应该需要多个卷积核,这就是为什么需要学习多个卷积核的原因。
还有一个问题,那就是为什么CNN要设计这么多层呢?首先,应该要明白,猫的头是一个特征,但是对于充斥着像素点的图像来说,用几个卷积核直接判断存在一个猫头的还是太困难,怎么办?简单,把猫头也作为一个识别目标,比如猫头应该具有更底层的一些语义特征,比如应该有猫的眼睛、猫的耳朵、猫的鼻子等等。这些特征有的还是太高级了,没关系,继续向下寻找低级特征,一直到最低级的像素点,这样就构成了多层的神经网络。
最好,CNN最不好理解的就要放大招了。虽然我们之前一直用一些我们人常见的语义特征做例子,但是实际上CNN会学习出猫头、猫尾巴、猫身然后经判定这是猫吗?显然我们的CNN完全不知道什么叫猫头、猫尾巴,也就是说,CNN不知道什么是猫头猫尾巴,它学习到的只是一种抽象特征,甚至可能有些特征在现实世界并没有对应的名词,但是这些特征组合在一起计算机就会判定这是一只猫!关于这一点,确实有些难以理解,比如一个人判断猫是看看有没有猫头、猫身子、猫尾巴,但是另一个选取的特征就是有没有猫的毛,猫的爪子,还有的人更加奇怪,他会去通过这张图像里是不是有老鼠去判断,而我们的CNN,则是用它自己学习到的特征去判断。
———————————分割线——————————————————————
最近又看了一些资料,在此纠正和阐明一些问题。
目前CNN的可视化是一个很火的方向了,有些论文中已经提到了中间的卷积层特征其实也是具有现实的语义意义的,但是只是不那么清晰。
CNN称之为深度学习,要义就在这个深字上,对于CNN而言,这个深其实就是意味着层层的特征表示。比如浅层的特征,例如点、线、面之类的简单几何形状,都是在底层训练出来的,对于这些底层的特征继续进行组合表示,就是后面的若干层的任务。最后把从低级特征组合而来的高级特征在进一步变成语义特征,就可以使用全连接层进行分类了。也就是说,最后一次分类并不一定要用神经网络,如果已经拿到了足够好的特征信息,使用其余的分类器也未尝不可。
这就是为什么CNN可以fine-tune的原因,例如你要完成一个分类猫和狗的任务,你需要从头训练一个CNN网络吗?假设你的猫狗图片样本量并不是很大,这并不是一个好主意。好的办法是,拿一个经过大型图像数据集,你如ImageNet,训练过的大规模CNN(比如VGG NET)直接载入训练,这个过程称之为fine-tuning。因为这个CNN底层已经训练到了丰富的细节信息,你所需要训练的其实是上层对这些特征的组合信息,以及最后全连接层的分类信息,所以完全不需要从头再来。这也证明了CNN确实可以有迁移学习的能力。
———————————分割线——————————————————————
之前有一点没有说,今天没啥事补充一下,也算是做个记录。
CNN的部件其实大致分为三个,卷积层、池化层、全连接层,这也是LeNet-5的经典结构,之后大部分CNN网络其实都是在这三个基本部件上做各种组合和改进。卷积层之前已经介绍过了,全连接层就是连在最后的分类器,是一个普通的bp网络,实际上如果训练得到的特征足够好,这里也可以选择其他的分类器,比如SVM等。
那么池化层是干什么的呢?池化,英文是pooling,字面上看挺难懂,但其实这可能是CNN里最简单的一步了。我们可以不按字面理解,把它理解成下采样(subsampling)。池化分为最大值池化和平均值池化,和卷积差不多,也是取一小块区域,比如一个5*5的方块,如果是最大值池化,那就选这25个像素点最大的那个输出,如果是平均值池化,就把25个像素点取平均输出。
这样做有什么好处呢?1、应该很明显可以看出,图像经过了下采样尺寸缩小了,按上面的例子,原来5*5的一个区域,现在只要一个值就表示出来了!2、增强了旋转不变性,池化操作可以看做是一种强制性的模糊策略,举个不恰当的例子,假设一个猫的图片,猫的耳朵应该处于左上5*5的一个小区域内(实际上猫的耳朵不可能这么小),无论这个耳朵如何旋转,经过池化之后结果都是近似的,因为就是这一块取平均和取最大对旋转并不care。
当然和之前的卷积一样,池化也是层层递进的,底层的池化是在模糊底层特征,如线条等,高层的池化模糊了高级语义特征,如猫耳朵。所以,一般的CNN架构都是三明治一样,卷积池化交替出现,保证提取特征的同时也强制模糊增加特征的旋转不变性。
更新一下比较advantage的东西。
现代CNN相比于之前的远古CNN发生了很大变化,虽然这里的远古CNN大约在2014年论文中出现,距今也只有不到4年时间。这里也可以看出深度学习的发展日新月异,一日千里的可怕速度。
理解了本身CNN的基础含义,再来看看这些先进的CNN,是很有必要的,不要指望只靠卷积层池化层就可以得到好的效果,后来加入CNN的trick不计其数,而且也都是里程碑式的成果。下面主要以图像分类的CNN来阐述。
暴力加深流派:以AlexNet和VGGNet为首的模型,这一派观点很直接,就是不断交替使用卷积层池化层,暴力增加网络层数,最后接一下全连接层分类。这类模型在CNN早期是主流,特点是参数量大,尤其是后面的全连接层,几乎占了一般参数量。而且相比于后续的模型,效果也较差。因此这类模型后续慢慢销声匿迹了。
Inception流派:谷歌流派,这一派最早起源于NIN,称之为网络中的网络,后被谷歌发展成Inception模型(这个单词真的不好翻译。。。)。这个模型的特点是增加模型的宽度,使得模型不仅仅越长越高,还越长越胖。也就是说每一层不再用单一的卷积核卷积,而是用多个尺度的卷积核试试。显然,如果你熟悉CNN,就不难发现,这样做会使每一层的feature map数量猛增,因为一种尺寸的卷积核就能卷出一系列的feature map,何况多个!这里google使用了1*1的卷积核专门用来降channel。谷歌的特点是一个模型不玩到烂绝不算完,所以又发展出了Inception v2、Inception v3、Inception v4等等。
残差流派:2015年ResNet横空出世,开创了残差网络。使用残差直连边跨层连接,居然得到了意想不到的好效果。最重要的是,这一改进几乎彻底突破了层数的瓶颈,1000层的resnet不是梦!之后,最新的DenseNet丧心病狂地在各个层中间都引入了残差连接。目前大部分模型都在尝试引入残差连接。
注意,到此为止,大部分模型已经丢弃了全连接层,改为全局平均池化。大大降低了参数量。
混合流派:这一派不说了,就是看到哪几类模型效果好,就把这类技术混杂起来。典型的就是Xception和ResIception,将Inception和残差网络结合起来了。
BatchNromalization:不得不提这个批量标准化技术,在此技术出现之前,CNN收敛很慢,此技术出现后,大大加快了模型收敛速度,还兼具一定的防过拟合效果。当然,这个技术不仅仅限于CNN。