为什么要使用MCMC方法?
19 个回答

这是一个非常好的问题。
MCMC的应用是和"维数灾难"有关的。考虑一个R上的分布,如果我们要计算它的数学期望,采用题主所描述的"等距计算",那么取100个点大致可以保证精度。然而考虑一个R^50的分布,这时候要采用"等距计算"就要在每个维度上取100个点,这样一来就要取10^100个点。作为对比,已知宇宙的基本粒子大约有10^87个。
如果仔细观察"等距计算"的结果,就会发现绝大多数点算出的概率都很小,而少部分点的概率非常大。而如果我们忽略大多数概率小的点,只计算概率大的那小部分点,对最后数学期望的结果影响非常小。这是MCMC思路的直观部分。
MCMC应用的概率模型,其参数维数往往巨大,但每个参数的支撑集非常小。比如一些NLP问题的参数只取{0,1},但维数往往达到几千甚至上万左右,这正说明了MCMC更适用这些问题。

 (almost) Ergodic Re-samplerhttps://www.zhihu.com/video/1586429816370409472
(almost) Ergodic Re-samplerhttps://www.zhihu.com/video/1586429816370409472Prelude
前面[1]我引用了 Jaynes 的观点 ——
It appears to be a quite general principle that, whenever there is a randomized way of doing something, then there is a nonrandomized way that delivers better performance but requires more thought.
把它倒过来读,再翻译成人话,可以这样解读 ——
如果不想烧掉自己的大脑,而且不介意牺牲性能,完全可以用随机(采样)的办法来解决问题嘛!
蒙特卡洛方法代表的正是这种简单粗暴的计算逻辑,当然它跟我经常说的力大飞砖是两码事。


从某种意义上说,它更像康斯坦丁·齐奥尔科夫斯基[2]建立火箭学之前的一种飞行思路。和空气动力学一样,这条路永远都无法将仰望星空的青蛙送进太空。


广义的 Monte Carlo Method 应该跟 Bayesian Theorem 一样古老,但是在上世纪中期才从一种手艺活演变成严格的计算工具[3]。Bayesian 看到 Monte Carlo 大概会直接脑补成 Markov Chain Monte Carlo,所以我也主要讨论 MCMC。无它,MCMC 受到了 Ergodic Theorem 和大数定理的赐福,俨然是 Bayesian Way 的一种正统[4]。要讨论 Ergodic Theorem 必须回到统计力学和动力学系统,并且再一次提及 von Neumann 这只青蛙。这涉及我完全不了解的 George D. Birkhoff,以及我同样不熟悉但是私自封圣的 Bernard O. Koopman [5]—— 总之我跑题了。在一个 Bayesian 修正主义者眼里,这个定理属于典型的马后炮,是统计物理学家为了给自己搞的近似正名折腾出来的补丁。而且这么一帮大佬亲自下场,也只是把 Ergodicity 的假设变成了 Weak Mixing 的假设 —— 如果不是 Strong Mixing 的话。
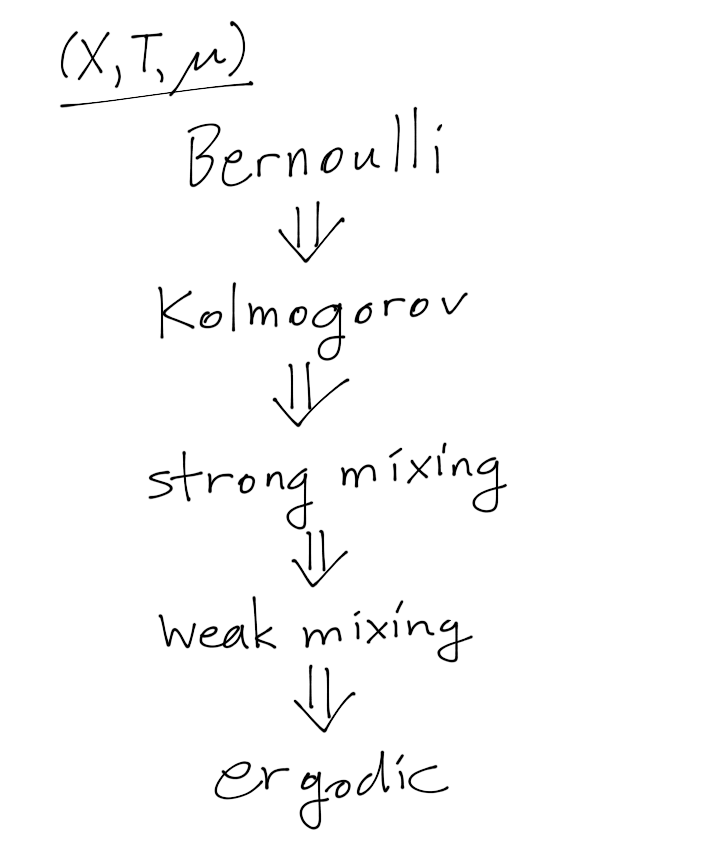

在 MCMC 中,Ergodicity 是通过构造获得的,其中涉及的随机过程压根就叫 Ergodic Process,并不需要引用 Ergodic Theorem。
Stanislaw Ulam and Nicholas Metropolis
理论上我可以只提 Nicholas Metropolis 这只青蛙,因为最经典的 Metropolis Sampling[6] 跟 Ulam 没关系,倒是跟一个叫 Keith Hasting 的家伙[7]有关系。据说,现代的 Monte Carlo Method 是这两只青蛙跟 von Neumann 在曼哈顿计划中,为模拟中子扩散发展出的一种统计方法[8]。


MCMC 方法当然是一种适用性极广的计算工具,以至于有些人觉得它是普适的——

简单的说,MCMC 已经是现代 Bayesian 工具箱里面的一把瑞士军刀,一个 Bayesian 计算框架不支持 MCMC 都不好意思跟人打招呼。Mathematica、Matlab 这些就不说了,Python 的就有 PyMC、Pyro,C++ 的有 STAN。在这个领域,我是货真价实的井底之蛙;MCMC 的世界实在是太广阔了,实在是没有能力尬吹[9]。
在低自由度的问题上,采样的主流已经不再是 Metropolis Algorithm 这样的随机漫步,而是 Hamiltonian Monte Carlo 这类能更好地利用信息的采样算法[10]。引用某一只青蛙的原话,“Why Walk When You Can Flow?”[11]。
Encore
我对 MCMC 的态度,大概是 Curt Monash 评价 MOLAP 的温和版[12]。
That ship has sailed … and foundered … and been towed to drydock.
声明:我没这么刻薄和极端,最近还在 GPU 上算 MOLAP,只是不折腾 relational algebra 罢了。
我之前有一个偏见,以为 MCMC 的问题在于很难 GPU 加速。但是这个说法过于温和,所以这里抛出一些板砖来娱乐众蛙。MCMC 本身没有任何问题,但是想用 MCMC 来计算高维流形上的配分函数 Z,从而计算后验分布、估算后验概率,大体上相当于发展空气动力学来登月。


本蛙最初做的也是小自由度的优化问题,所以长期认为 MCMC 这类计算工具只是受制于 Curse of Dimensionality,如果不考虑计算成本,改进一下算法总是能解决更复杂的问题。但是被统计力学和量子力学洗脑之后,我才发现这完全是个误会,最根本的问题是高维空间跟低维空间有着本质的区别,more is different。


最根本的原因还是个高维空间的测度问题 —— 必须先定义一个测度空间才能分配概率。而一般的测度在高维空间里面是病态的[13],不管是用 MCMC 还是更一般的 Langevin Dynamics 来采样,得到的单个样本其测度几乎一定是 0。只有当采样的样本在一个性质足够好的低维流形上的时候,才能把低自由度的那套把戏搬过来。
抛开上述问题不谈,假设存在一个理想的 Hamiltonian Dynamics 引导我们在高维空间中采集样本,它不仅对初值不敏感、对微扰也不敏感,暂时忽略数值计算的误差和所需的电费。那么是否可以计算配分函数 Z 和计算某个样本邻域的后验概率?作为一个 Bayesian,我的回答只能是不一定。这跟先验分布(初始值)和动力学系统的吸引子结构有关系。除非先验分布的信息量和吸引子结构的信息量足够小,我们近似计算配分函数所需要的样本量很可能是个天文数字[14]。
当然有人可能知道我说的是理想化的 Latent Diffusion Model,我的出发点必然也只能是 Stable Diffusion。在具体的 Stable Diffusion 采样中[15],任何一个合法的初始条件[16]都能采样出几乎无关的样本。即便我们假装它是个 ODE 形式化的采样过程,有且仅有一个解,所有可能的样本也是近乎无穷的[17]。
甚至在确定初始条件的前提下,这个吸引子结构[18]都可能复杂到很难用一个简单的算法进行探索。当然 Stable Diffusion 中并不存在显著的混沌现象和分形结构,所以只要愿意出电费应该可以搞清楚单个初始条件的吸引子结构[19]。当然,即便是我这种致力于研究 Stable Diffusion 中的动力学过程的青蛙,也不愿意去做这类吃力不讨好的事情。
退一万步说,即便只需要采样几百万张图片,然后通过某种神奇的算法计算某个样本跟这些图片的相似度,能吐出一个概率,就真的会有人去算了么?又有任何人能够直观地理解这个分布么?


总是存在一些原教旨的 Bayesian,看到 MAP 就条件反射地把一顶叫 Point Estimation 的帽子扣上去,就好像他真的能算出个高维流形上的后验分布一样。引用 Noam Chomsky 的暴论作为结语[20] ——
Science talks about very simple things, and asks hard questions about them. As soon as things become too complex, science can't deal with them. The reason why physics can achieve such depth is that it restricts itself to extremely simple things, abstracted from the complexity of the world. As soon as an atom gets too complicated, maybe helium, they hand it over to chemists. When problems become too complicated for chemists, they hand it over to biologists. Biologists often hand it over to the sociologists, and they hand it over to the historians, and so on. But it's a complicated matter: Science studies what's at the edge of understanding, and what's at the edge of understanding is usually fairly simple. And it rarely reaches human affairs. Human affairs are way too complicated. In fact even understanding insects is an extremely complicated problem in the sciences. So the actual sciences tell us virtually nothing about human affairs.
参考
- ^这是专栏文章灌水骗赞的,前文在专栏里面。 https://zhuanlan.zhihu.com/p/590341035
- ^Константин Эдуардович Циолковский
- ^当然这跟数学家的严格是两码事。
- ^比如圣诞节这种异教节日也是基督教不可分割的传统嘛。
- ^https://zhuanlan.zhihu.com/p/82666747
- ^https://arxiv.org/pdf/1704.04629.pdf
- ^此人搞不好并不是 Bayesian,而是个异端。
- ^https://zhuanlan.zhihu.com/p/223042372
- ^我更擅长也更喜欢吐槽,尤其喜欢随机采样出来的一本道(以前的说法是脸滚键盘)。 https://www.zhihu.com/question/49044755/answer/2752225155
- ^更具体的说,是 No U-Turn Sampler。 https://arxiv.org/abs/1111.4246
- ^可视化非常好,建议洗脑循环。 https://elevanth.org/blog/2017/11/28/build-a-better-markov-chain/
- ^http://www.dbms2.com/2012/11/05/do-you-need-an-analytic-rdbms/
- ^https://www.zhihu.com/question/32210107
- ^当然大数爱好者眼里根本不值一提。
- ^模型、输入、采样策略、采样参数全都确定。
- ^以及它们不合法的微扰。
- ^其中当然存在重复和雷同的样本,但是这并不影响讨论。
- ^或者说分布,或者说测地线,都没区别。
- ^当然也得有前提条件,比如微扰的强度必须是确定的,边界条件不能是任意的。
- ^https://chomsky.info/20060301/