
seq2seq中的beam search算法过程


在sequence2sequence模型中,beam search的方法只用在测试的情况,因为在训练过程中,每一个decoder的输出是有正确答案的,也就不需要beam search去加大输出的准确率。
假设现在我们用机器翻译作为例子来说明,
我们需要翻译中文“我是中国人”--->英文“I am Chinese”
假设我们的词表大小只有三个单词就是I am Chinese。那么如果我们的beam size为2的话,我们现在来解释,
如下图所示,我们在decoder的过程中,有了beam search方法后,在第一次的输出,我们选取概率最大的"I"和"am"两个单词,而不是只挑选一个概率最大的单词。
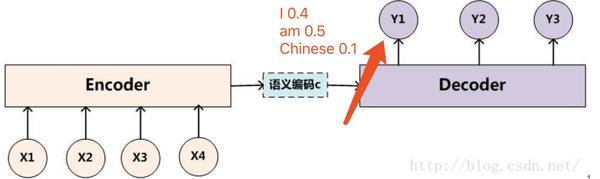

然后接下来我们要做的就是,把“I”单词作为下一个decoder的输入算一遍得到y2的输出概率分布,把“am”单词作为下一个decoder的输入算一遍也得到y2的输出概率分布。
比如将“I”单词作为下一个decoder的输入算一遍得到y2的输出概率分布如下:
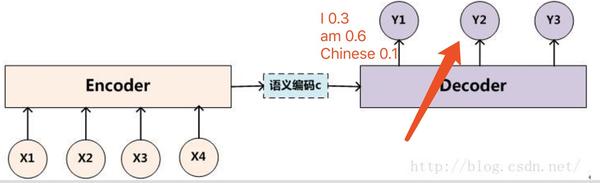

比如将“am”单词作为下一个decoder的输入算一遍得到y2的输出概率分布如下:
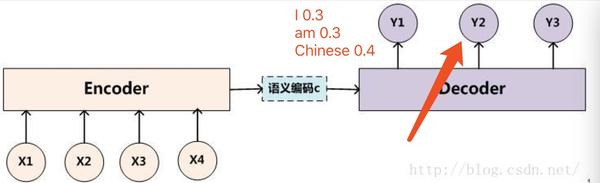

那么此时我们由于我们的beam size为2,也就是我们只能保留概率最大的两个序列,此时我们可以计算所有的序列概率:
“I I” = 0.4*0.3 "I am" = 0.4*0.6 "I Chinese" = 0.4*0.1
"am I" = 0.5*0.3 "am am" = 0.5*0.3 "am Chinese" = 0.5*0.4
我们很容易得出俩个最大概率的序列为 “I am”和“am Chinese”,然后后面会不断重复这个过程,直到遇到结束符为止。
最终输出2个得分最高的序列。
这就是seq2seq中的beam search算法过程,但是可能有些同学有一个疑问,就是但i-1时刻选择的单词不同的时候,下一时刻的输出概率分布为什么会改变?
这是由于解码的过程中,第i时刻的模型的输入,包括了第i-1时刻模型的输出,那么很自然在第i-1时刻模型的输出不同的时候,就会导致下一时刻模型的输出概率分布会不同,因为第
i-1时刻的输出作为参数影响了后一时刻模型的学习。
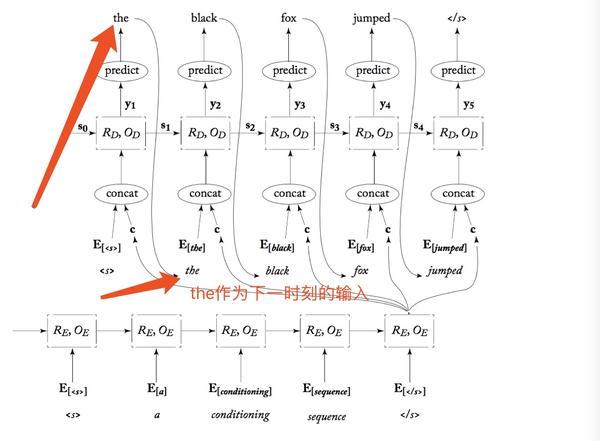
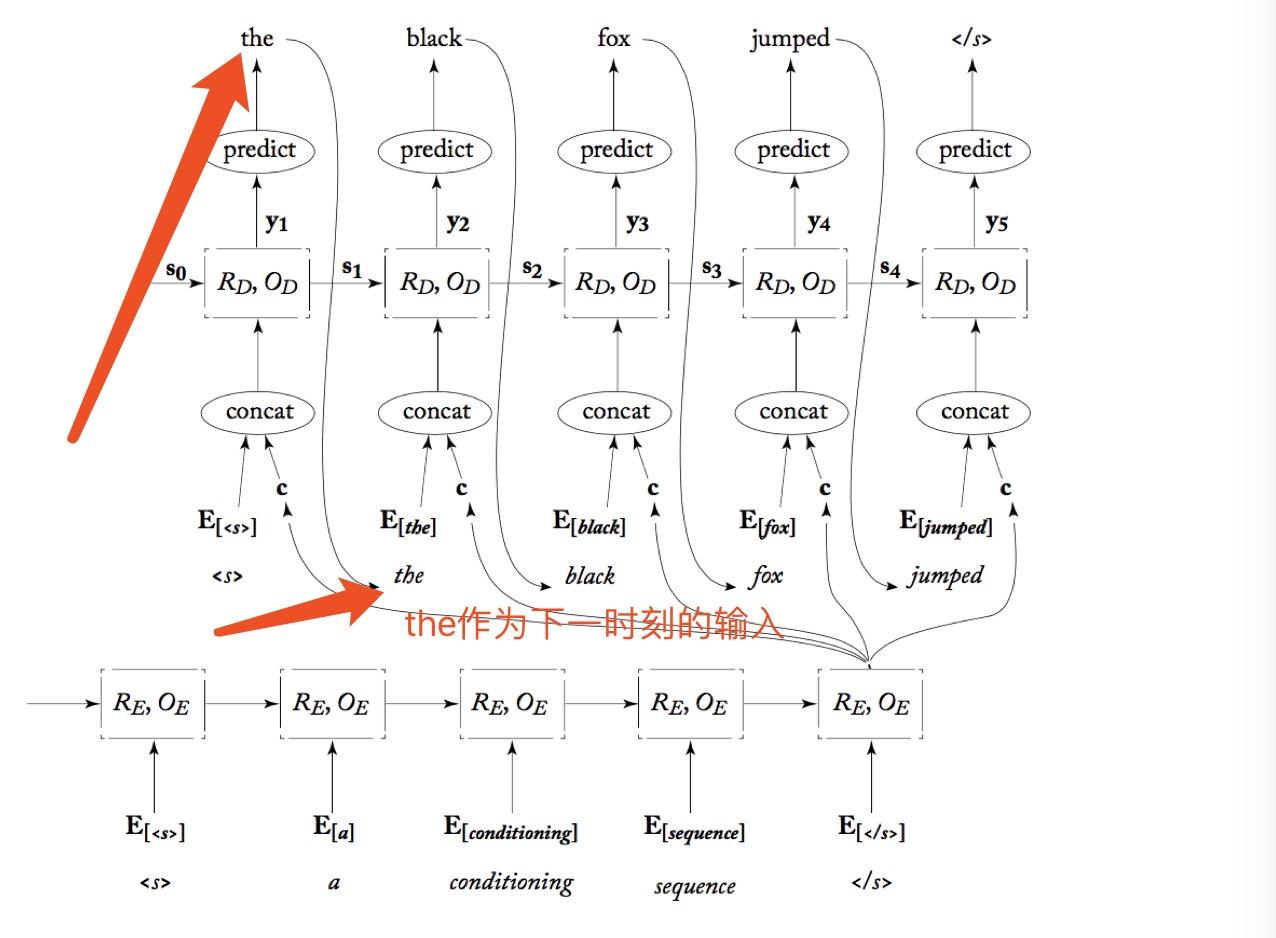
如下图用了一个slides的法语翻译为英文的例子,可以更容易理解上面的解释。
致谢:
凌志、刘洋、皓宇、萧瑟师兄
