携程安全自动化测试之路

一、背景
业务代码上线前,通常会在测试环境经过一系列的功能测试。那么,从安全层面来说,web应用常见的web漏洞,如sql注入,xss攻击,敏感信息泄漏等,我们如何保证在上线前就能够自动化发现这些业务的安全漏洞呢?本文将详细讲述携程安全测试的自动化之路。
二、技术选型
市面上也有很多各种各样的开源、商业扫描器。单就应用这一层来说,漏洞扫描器一般分为主动扫描和被动扫描两种。
其中,主动扫描一般用于黑盒测试,其形式为提供一个URL入口地址,然后由扫描器中的爬虫模块爬取所有链接,对GET、POST等请求进行参数变形和污染,进行重放测试,然后依据返回信息中的状态码、数据大小、数据内容关键字等去判断该请求是否含有相应的漏洞。
另外一种常见的漏洞扫描方式就是被动扫描,与主动扫描相比,被动扫描并不进行大规模的爬虫爬取行为,而是直接通过捕获测试人员的测试请求,直接进行参数变形和污染来测试服务端的漏洞,如果通过响应信息能够判断出漏洞存在,则进行记录管理,有人工再去进行漏洞的复现和确认。
所以我们可以发现,主动扫描与被动扫描最主要的区别为被动式扫描器不主动获取站点链接,而是通过流量、获取测试人员的访问请求等手段去采集数据源,然后进行类似的安全检测。
除此之外,基于主动扫描的web扫描器还有其他的不足:
- 由于数据源来自爬虫爬取,独立的页面、API接口等就无法覆盖,存在检测遗漏情况。
- 如果是扫描单独的几个站点,主动扫描是够用的。但是在站点数量急剧增大的时候,主动扫描的效率、精准、速度都无法与被动扫描相比。
最终我们选择基于被动扫描的形式去实现自研web漏洞扫描器。
三、架构设计
基于以上自动化的安全检测需求,由我们内部研发了Hulk项目,通过网络流量镜像等方式来实现分布式的实时Web漏洞扫描系统。整个项目按模块可分为数据源,数据处理,漏洞检测,漏洞管理等几大模块。
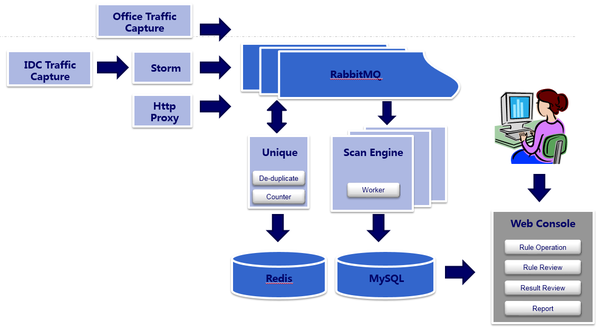

如图所示,Http请求数据从数据源发送至Rabbitmq、Kafka等队列。交由统计、去重、去静态资源模块利用redis进行数据处理,处理后的unique请求存入Rabbitmq扫描队列,等待scan engine的消费。而scan engine则全权负责参数解析和变形,利用预先设置好的规则顺序进行请求重放和漏洞检测。最终,如果Scan engine判断出某个请求含有漏洞,则落地到MySQL中,交由Hulk的运营人员进行漏洞的确认和复现。
四、数据源
数据来源主要有2种类型,即基于网络流量镜像的方式和基于Http代理的方式。
基于网络流量镜像的方式中,需要在办公网到测试环境核心交换机上做流量镜像,通过dpdk、pf_ring等高速抓包模块进行流量获取,并按照五元组信息进行tcp流重组。然后通过http解析器,将其中http请求的请求方法、请求地址、请求域名、请求参数等数据提取成json格式,发送到kafka中。
当然,这其中还有一部分为https的请求,需要通过rsa key解密后才能交由http解析器正常解析。随着http2.0时代的来临,大部分的https请求在进行秘钥交换时采用了更高安全性的Diffie-Hellman秘钥交换算法,我们的https解密模块也逐渐退出历史舞台,只能后移流量镜像模块,转向纯Http的流量捕获。
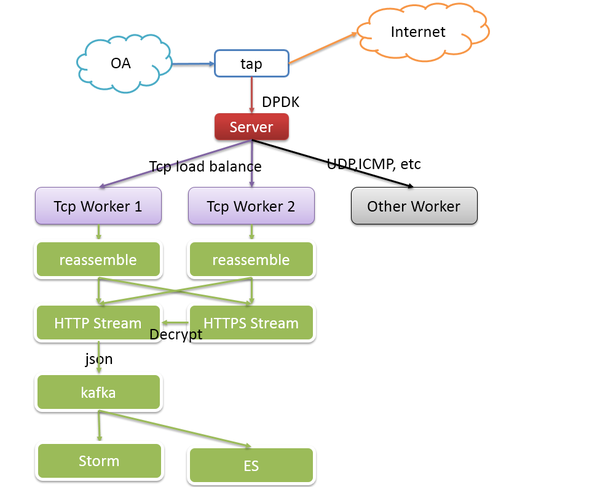

基于Http代理的方式中,只需要配置代理服务器,将测试人员的测试请求数据收集起来,然后采用同样的模块进行去重和统计处理,结果发送至Kafka队列,有着与基于流量的形式同样的处理流程。
五、数据处理
流量进入到消息队列之后,去重模块会从消息队列消费,计算出url、args等的MD5值,在redis中进行去重,如果是一个已经扫描过的地址,则只记录一条日志到ES中;如果是一个新的URL地址,就将其具体的HTTP请求发送至消息队列中,等待scan engine的消费。
在数据处理的时候,去重是非常重要的,这里涉及到不同请求方法、不同的参数,任何一点不同,都可以被看重是不同的URL地址,也对应了不同的后端接口。

除了这些之外,针对伪静态URL,我们也需要将/products/655554.html归一化为/products/NNNNN.html。如上图所示,将数字归一化来去掉30%左右的相似URL。然后利用redis的TTL特性,使得一段时间之前扫过的URL,可以在下一次的去重中被判断为新URL,从而再次加入扫描队列,等待新一轮的安全检测。
六、漏洞检测
扫描引擎从消息队列中读取去重后的流量数据,使用多种不同的方式去进行漏洞扫描。
- 一般的web漏洞配置规则来检查,比如xss漏洞, 文件包含漏洞,敏感文件读取等,先替换参数,或重新构造URL, 再重放, 再检查响应内容是否包含特定的信息, 以此来判断是否存在漏洞;
- sql注入漏洞则使用高效的开源工具sqlmap来检测,避免重复造轮子;
- 另外还有一些其他漏洞,比如存储型xss,struts漏洞,ssl的漏洞,这些无法使用简单的替换参数重放的方法,但是我们提供了插件编写功能,这样可以让运营人员写插件,以满足各种需求。
但是,从storm实时攻击检测系统过来的流量是不带cookie的, 如何扫描登录后漏洞呢?我们生产url和测试url可以通过一种映射关系进行转换,保存各个测试站点的登陆信息文件。当读取一个生产的url后,去获取它的测试地址和登录信息,就可以去扫描它相应的测试地址了。这样就避免了影响线上用户。


扫描速度也是扫描任务的一个关键指标,在整个架构中,不同的模块之间是通过消息队列进行数据传输的。所以当去重模块或者扫描引擎模块处理速度不够快,造成数据积压时,我们可以通过增加模块实例来进行水平拓展。
七、漏洞管理
对于扫描结果中存在问题的URL和对应漏洞,我们会进行一个快照功能。即将当时的请求和响应包完整保存下来,方便运营人员验证漏洞。
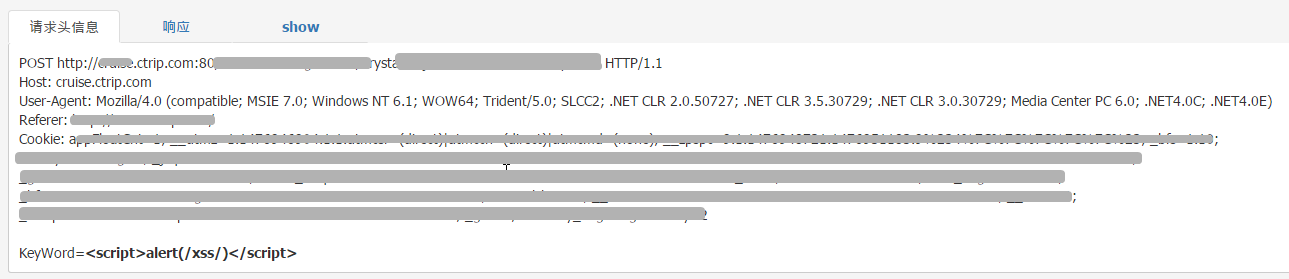

且对于响应体内容,还可以进行一个基本的本地渲染,复现漏洞发现时的真实情况。
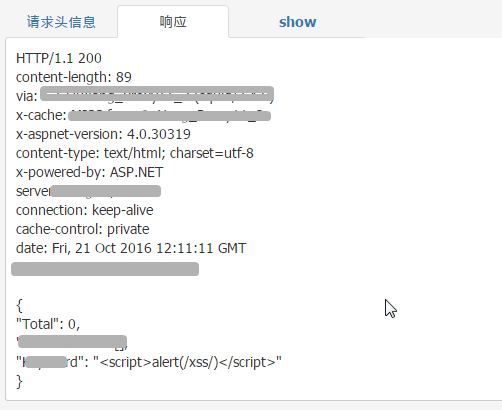

八、规则测试
同时,为保证规则有效性,我们还在管理控制台中集成了规则的测试功能:

这样,只需要搭建一个带各种漏洞的测试环境,规则运营人员就可以在这里配置, 然后针对性地对每一个规则、插件进行有效性测试。
九、总结
目前,整个项目上线稳定运行两年多,已发现线上高危漏洞30+,中危漏洞300+,低危漏洞 400+,为线上业务安全运行提供了强有力的保障。当然, 对于数据污染、扫描频率、去重逻辑、扫描类型等扫描器常见的诟病,我们后续也会一直不断进行优化迭代。
【作者简介】陈莹,携程信息安全部安全开发工程师。2013年加入携程,主要负责各类安全工具的研发,包括线上日志异常分析,实时攻击检测, 漏洞扫描等。
没看够?更多来自携程技术人的一手干货,欢迎搜索关注“携程技术中心”微信公号哦~
