
基于R语言的信用评分卡建模分析

信用评分技术是一种应用统计模型,其作用是对贷款申请人(信用卡申请人)做风险评估分值的方法。信用评分卡可以根据客户提供的资料、客户的历史数据、第三方平台(芝麻分、京东、微信等)的数据,对客户的信用进行评估。信用评分卡的建立是以对大量数据的统计分析结果为基础,具有相当高的准确性和可靠性。
本文通过对kaggle上的Give Me Some Credit数据的挖掘分析,结合信用评分卡的建立原理,从数据的预处理、建模分析、创建信用评分卡到建立自动评分系统,创建了一个简单的信用评分系统。并对建立基于AI 的机器学习评分卡系统的路径进行推测。
1.工作原理
客户申请评分卡是一种统计模型,它可基于对当前申请人的各项资料进行评估并给出一个分数,该评分能定量对申请人的偿债能力作出预判。
客户申请评分卡由一系列特征项组成,每个特征项相当于申请表上的一个问题(例如,年龄、银行流水、收入等)。每一个特征项都有一系列可能的属性,相当于每一个问题的一系列可能答案(例如,对于年龄这个问题,答案可能就有30岁以下、30到45等)。在开发评分卡系统模型中,先确定属性与申请人未来信用表现之间的相互关系,然后给属性分配适当的分数权重,分配的分数权重要反映这种相互关系。分数权重越大,说明该属性表示的信用表现越好。一个申请的得分是其属性分值的简单求和。如果申请人的信用评分大于等于金融放款机构所设定的界限分数,此申请处于可接受的风险水平并将被批准;低于界限分数的申请人将被拒绝或给予标示以便进一步审查。
2.预处理
2.1数据导入
#载入数据
cs_training <- read.csv('cs_training.csv')
#去掉第一列
cs_training<- cs_training[,-1]2.2数据预处理
2.2.1缺失值处理
#查看数据集缺失数据
missmap(cs_training,main = "Missing values vs observed")
#缺失值级联表
md.pattern(cs_training)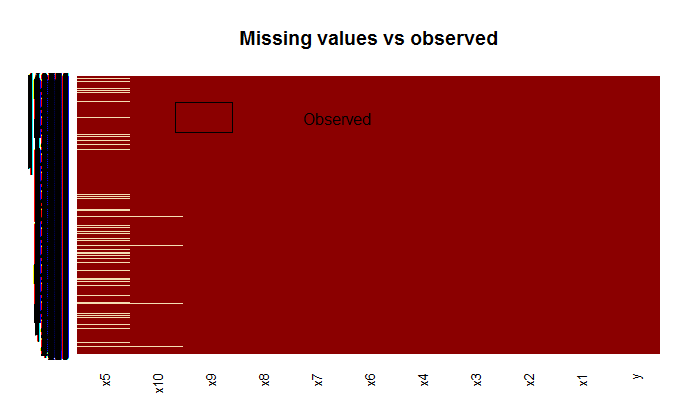

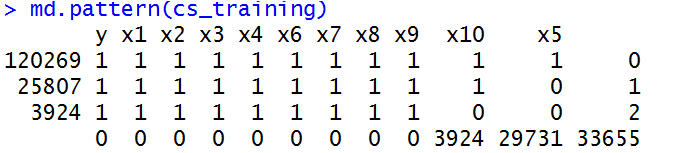

利用missmap函数对缺失值部分进行可视化展示,可以看到x5变量和x10变量有缺失值,即MonthlyIncome变量和NumberOfDependents两个变量存在缺失值,具体确实情况可以见上表,monthlyincome列共有缺失值29731个,numberofdependents有3924个。
#x5(MonthlyIncome)缺失值处理(使用中位数)
cs_training$x5 <- na.roughfix(cs_training$x5)
#x10(NumberOfDependents)3924个缺失值,所占比重3924/150000不大,故直接删除
cs_training <- cs_training[!is.na(cs_training$x10),]2.2.2异常值处理
首先对于x2变量,即客户的年龄,我们可以定量分析,发现有以下值:
#对x2变量(客户的年龄)定量分析
unique(cs_training$x2)

可以看到年龄中存在0值,显然是异常值,予以剔除。
cs_training<-cs_training[-which(cs_training$x2==0),]而对于x3,x7,x9三个变量,由下面的箱线图可以看出,均存在异常值,且由unique函数可以得知均存在96、98两个异常值,因此予以剔除。同时会发现剔除其中一个变量的96、98值,其他变量的96、98两个值也会相应被剔除
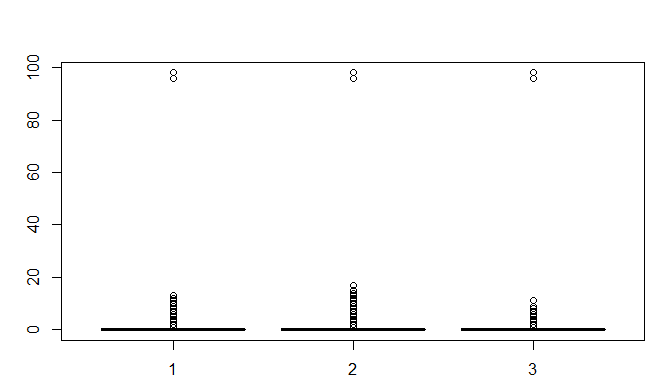



#去掉异常值96和98
#因为有96和98值的x3、x7、x9是在同一行,所以动一个变量即可
cs_training<-cs_training[-which(cs_training$x3==96),]
cs_training<-cs_training[-which(cs_training$x3==98),]其它变量暂不作处理。
2.2.3单变量分析
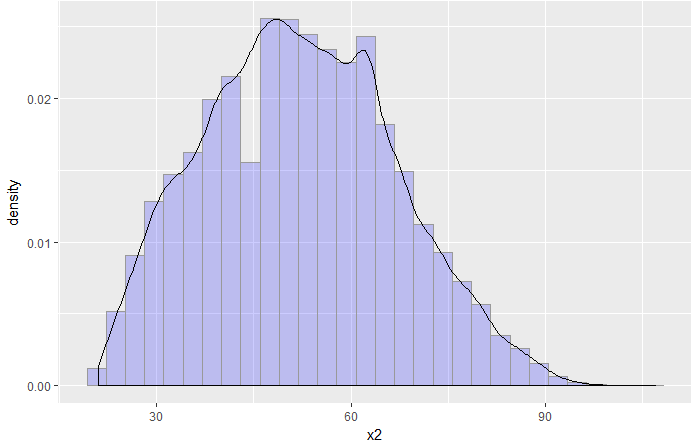

可以看到年龄变量大致呈正态分布,符合统计分析的假设。
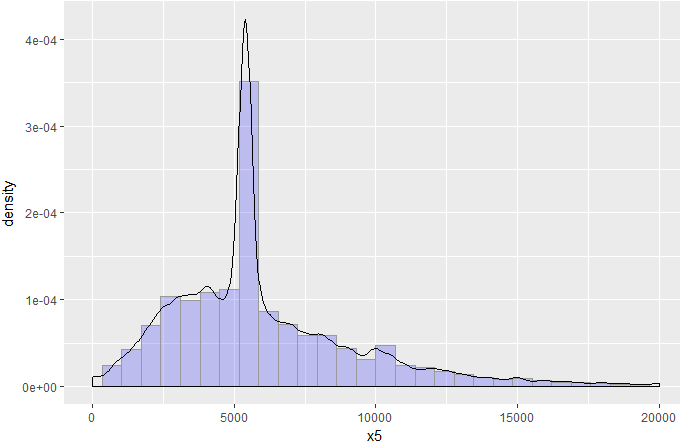

月收入也大致呈正态分布,符合统计分析的需要。
2.2.4变量相关性分析
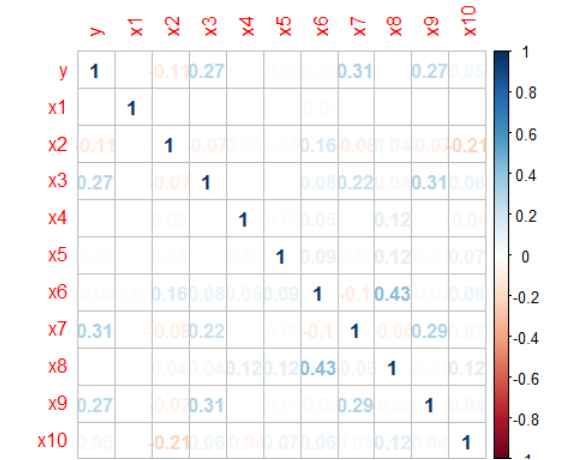

由上图可以看出,各变量之间的相关性是非常小的。其实Logistic回归同样需要检验多重共线性问题,不过此处由于各变量之间的相关性较小,可以初步判断不存在多重共线性问题,当然我们在建模后还可以用VIF(方差膨胀因子)来检验多重共线性问题。如果存在多重共线性,即有可能存在两个变量高度相关,需要降维或剔除处理。
2.3切分数据集


由上表看出,对于响应变量SeriousDlqin2yrs,存在明显的类失衡问题,SeriousDlqin2yrs等于1的观测为9712,仅为所有观测值的6.6%。因此我们需要对非平衡数据进行处理,在这里可以采用SMOTE算法,用R对稀有事件进行超级采样。
我们利用caret包中的createDataPartition(数据分割功能)函数将数据随机分成相同的两份。
set.seed(1234)
splitIndex<-createDataPartition(cs_training$y,time=1, p=0.5,list=FALSE)
train<-cs_training[splitIndex,]
test<-cs_training[-splitIndex,] 对于分割后的训练集和测试集均有72919个数据,分类结果的平衡性如下:
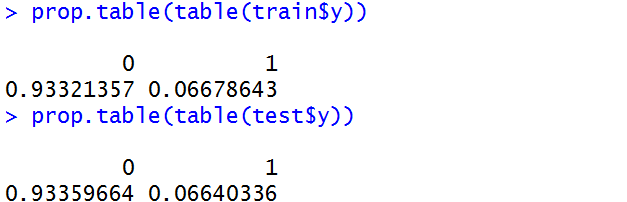

两者的分类结果是平衡的,仍然有6.6%左右的代表,我们仍然处于良好的水平。因此可以采用这份切割的数据进行建模及预测。
2.4特征变量选择
全变量建模
fit<-glm(y~.,train,family = "binomial")
summary(fit)

可以看出,利用全变量进行回归,模型拟合效果并不是很好,其中x1,x4,x6三个变量的p值未能通过检验,在此直接剔除这三个变量,利用剩余的变量对y进行回归。
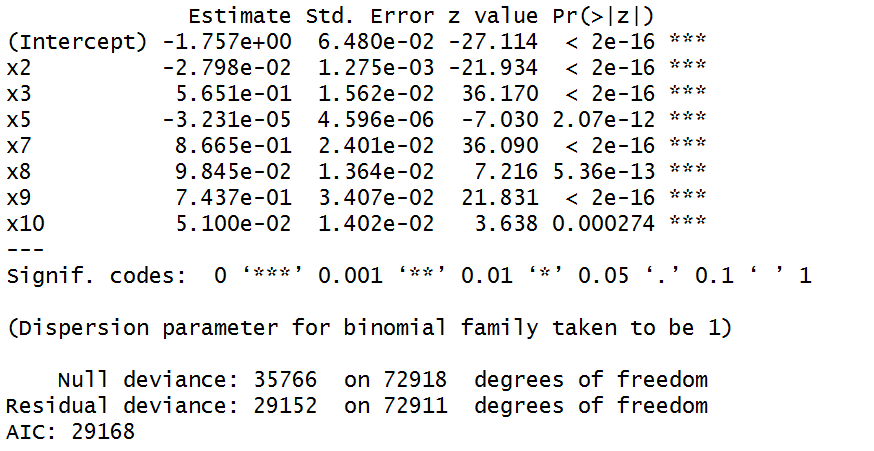

第二个回归模型所有变量都通过了检验,甚至AIC值(赤池信息准则)更小,所以特征变量选择x2+x3+x5+x7+x8+x9+x10。
2.5数据分箱
#age
cutx2= c(-Inf,30,35,40,45,50,55,60,65,75,Inf)
plot(cut(train$x2,cutx2))

#NumberOfTime30-59DaysPastDueNotWorse变量(x3):
cutx3 = c(-Inf,0,1,3,5,Inf)
plot(cut(train$x3,cutx3))

#MonthlyIncome变量(x5):
cutx5 = c(-Inf,1000,2000,3000,4000,5000,6000,7500,9500,12000,Inf)
plot(cut(train$x5,cutx5))

#NumberOfTimes90DaysLate变量(x7):
cutx7 = c(-Inf,0,1,3,5,10,Inf)
plot(cut(train$x7,cutx7))

#NumberRealEstateLoansOrLines变量(x8):
cutx8= c(-Inf,0,1,2,3,5,Inf)
plot(cut(train$x8,cutx8))

#NumberOfTime60-89DaysPastDueNotWorse变量(x9):
cutx9 = c(-Inf,0,1,3,5,Inf)
plot(cut(train$x9,cutx9))

#NumberOfDependents变量(x10):
cutx10 = c(-Inf,0,1,2,3,5,Inf)
plot(cut(train$x10,cutx10))

3.建模分析
3.1建模
fit2<-glm(y~x2+x3+x5+x7+x8+x9+x10,train,family = "binomial")
summary(fit2)3.2模型评估
下面首先利用模型对test数据进行预测,生成概率预测值
#利用模型对test数据进行预测,生成概率预测值
pre <- predict(fit2,test)在R中,可以利用pROC包,它能方便比较两个分类器,还能自动标注出最优的临界点,图看起来也比较漂亮。在下图中最优点FPR=1-TNR=0.842,TPR=0.639,AUC值为0.811,说明该模型的预测效果还是不错的,正确率较高。
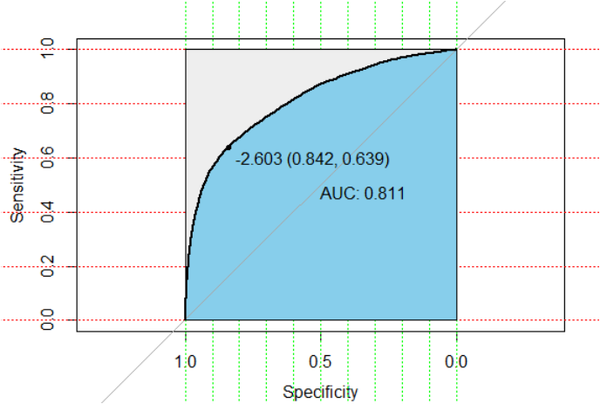

3.3特征属性woe计算
证据权重(Weight of Evidence,WOE)转换可以将Logistic回归模型转变为标准评分卡格式。引入WOE转换的目的并不是为了提高模型质量,只是一些变量不应该被纳入模型,这或者是因为它们不能增加模型值,或者是因为与其模型相关系数有关的误差较大,其实建立标准信用评分卡也可以不采用WOE转换。这种情况下,Logistic回归模型需要处理更大数量的自变量。尽管这样会增加建模程序的复杂性,但最终得到的评分卡都是一样的。
用WOE(x)替换变量x。WOE()=ln[(违约/总违约)/(正常/总正常)]。
通过上述的Logistic回归,剔除x1,x4,x6三个变量,对剩下的变量进行WOE转换。
#计算WOE的函数
totalgood = as.numeric(table(train$y))[1]
totalbad = as.numeric(table(train$y))[2]
getWOE <- function(a,p,q)
{
Good <- as.numeric(table(train$y[a > p & a <= q]))[1]
Bad <- as.numeric(table(train$y[a > p & a <= q]))[2]
WOE <- log((Bad/totalbad)/(Good/totalgood),base = exp(1))
return(WOE)
}比如age变量(x2)
#age变量(x2)
Agelessthan30.WOE=getWOE(train$x2,-Inf,30)
Age30to35.WOE=getWOE(train$x2,30,35)
Age35to40.WOE=getWOE(train$x2,35,40)
Age40to45.WOE=getWOE(train$x2,40,45)
Age45to50.WOE=getWOE(train$x2,45,50)
Age50to55.WOE=getWOE(train$x2,50,55)
Age55to60.WOE=getWOE(train$x2,55,60)
Age60to65.WOE=getWOE(train$x2,60,65)
Age65to75.WOE=getWOE(train$x2,65,75)
Agemorethan.WOE=getWOE(train$x2,75,Inf)
age.WOE=c(Agelessthan30.WOE,Age30to35.WOE,Age35to40.WOE,
Age40to45.WOE,Age45to50.WOE,Age50to55.WOE,
Age55to60.WOE,Age60to65.WOE,Age65to75.WOE,
Agemorethan.WOE)
age.WOE

NumberOfTime30-59DaysPastDueNotWorse变量(x3)
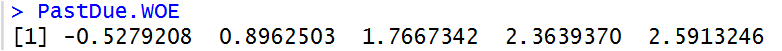

#MonthIncome变量(x5)


#NumberOfTime90DaysPastDueNotWorse变量(x7)


#NumberRealEstateLoansOrLines变量(x8)


#NumberOfTime60.89DaysPastDueNotWorse变量(x9)


#NumberOfDependents变量(x10)
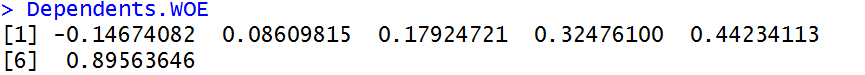

3.4评分卡创建
3.4.1创建评分标准




依据以上论文资料得到
a=log(p_good/P_bad)
Score = offset + factor * log(odds)
# 下面开始设立评分,假设按好坏比15为600分,
# 每高20分好坏比翻一倍算出factor,offset。如果后期结果不明显,
# 可以高30-50分好坏比才翻一倍。
620 = offset + factor * log(15*2,base = 10)
600 = offset + factor * log(15)
factor <- 20/(log(30,base = 10)-log(15,base = 10))
offset <- 600-factor*log(15,base = 10)
#个人总评分=基础分+各部分得分
#基础分为:
baseScore <- a*factor+offset3.4.2评分卡创建
#构造计算分值函数:
getscore<-function(i,x){
score = round(factor*as.numeric(coe[i])*x,0)
return(score)
}计算各变量分箱得分
#age变量(x2)
Agelessthan30.SCORE = getscore(2,Agelessthan30.WOE)
Age30to35.SCORE = getscore(2,Age30to35.WOE)
Age35to40.SCORE = getscore(2,Age35to40.WOE)
Age40to45.SCORE = getscore(2,Age40to45.WOE)
Age45to50.SCORE = getscore(2,Age45to50.WOE)
Age50to55.SCORE = getscore(2,Age50to55.WOE)
Age55to60.SCORE = getscore(2,Age55to60.WOE)
Age60to65.SCORE = getscore(2,Age60to65.WOE)
Age65to75.SCORE = getscore(2,Age65to75.WOE)
Agemorethan.SCORE = getscore(2,Agemorethan.WOE)
Age.SCORE = c(Agelessthan30.SCORE,Age30to35.SCORE,Age35to40.SCORE,
Age40to45.SCORE,Age45to50.SCORE,Age50to55.SCORE,
Age55to60.SCORE,Age60to65.SCORE,Age65to75.SCORE,
Agemorethan.SCORE)
Age.SCORE
#NumberOfTime30-59DaysPastDueNotWorse变量(x3)
PastDuelessthan0.SCORE =getscore(3,PastDuelessthan0.WOE/10)
PastDue0to1.SCORE = getscore(3,PastDue0to1.WOE/10)
PastDue1to3.SCORE = getscore(3,PastDue1to3.WOE/10)
PastDue3to5.SCORE = getscore(3,PastDue3to5.WOE/10)
PastDuemorethan.SCORE = getscore(3,PastDuemorethan.WOE/10)
PastDue.SCORE = c(PastDuelessthan0.SCORE,PastDue0to1.SCORE,
PastDue1to3.SCORE,PastDue3to5.SCORE,
PastDuemorethan.SCORE)
PastDue.SCORE
#MonthlyIncome变量(x5)
MonthIncomelessthan1000.SCORE = getscore(4,MonthIncomelessthan1000.WOE*1000)
MonthIncome1000to2000.SCORE = getscore(4,MonthIncome1000to2000.WOE*1000)
MonthIncome2000to3000.SCORE = getscore(4,MonthIncome2000to3000.WOE*1000)
MonthIncome3000to4000.SCORE = getscore(4,MonthIncome3000to4000.WOE*1000)
MonthIncome4000to5000.SCORE = getscore(4,MonthIncome4000to5000.WOE*1000)
MonthIncome5000to6000.SCORE = getscore(4,MonthIncome5000to6000.WOE*1000)
MonthIncome6000to7500.SCORE = getscore(4,MonthIncome6000to7500.WOE*1000)
MonthIncome7500to9500.SCORE = getscore(4,MonthIncome7500to9500.WOE*1000)
MonthIncome9500to12000.SCORE = getscore(4,MonthIncome9500to12000.WOE*1000)
MonthIncomemorethan.SCORE = getscore(4,MonthIncomemorethan.WOE*1000)
MonthIncome.SCORE = c(MonthIncomelessthan1000.SCORE,MonthIncome1000to2000.SCORE,
MonthIncome2000to3000.SCORE,MonthIncome3000to4000.SCORE,
MonthIncome4000to5000.SCORE,MonthIncome5000to6000.SCORE,
MonthIncome6000to7500.SCORE,MonthIncome7500to9500.SCORE,
MonthIncome9500to12000.SCORE,MonthIncomemorethan.SCORE)
MonthIncome.SCORE
#NumberOfTime90DaysPastDueNotWorse变量(x7)
Days90PastDuelessthan0.SCORE =getscore(5,Days90PastDuelessthan0.WOE/10)
Days90PastDue0to1.SCORE =getscore(5,Days90PastDue0to1.WOE/10)
Days90PastDue1to3.SCORE = getscore(5,Days90PastDue1to3.WOE/10)
Days90PastDue3to5.SCORE = getscore(5,Days90PastDue3to5.WOE/10)
Days90PastDue5to10.SCORE = getscore(5,Days90PastDue5to10.WOE/10)
Days90sPastDuemorethan.SCORE = getscore(5,Days90sPastDuemorethan.WOE/10)
Days90sPastDue.SCORE = c(Days90PastDuelessthan0.SCORE,Days90PastDue0to1.SCORE,
Days90PastDue1to3.SCORE,Days90PastDue3to5.SCORE,
Days90PastDue5to10.SCORE,Days90sPastDuemorethan.SCORE)
Days90sPastDue.SCORE
#NumberRealEstateLoansOrLines变量(x8)
RealEstatelessthan0.SCORE =getscore(6,RealEstatelessthan0.WOE)
RealEstate0to1.SCORE =getscore(6,RealEstate0to1.WOE)
RealEstate1to2.SCORE = getscore(6,RealEstate1to2.WOE)
RealEstate2to3.SCORE = getscore(6,RealEstate2to3.WOE)
RealEstate3to5.SCORE = getscore(6,RealEstate3to5.WOE)
RealEstatemorethan.SCORE = getscore(6,RealEstatemorethan.WOE)
RealEstate.SCORE = c(RealEstatelessthan0.SCORE,RealEstate0to1.SCORE,
RealEstate1to2.SCORE,RealEstate2to3.SCORE,
RealEstate3to5.SCORE,RealEstatemorethan.SCORE)
RealEstate.SCORE
#NumberOfTime60.89DaysPastDueNotWorse变量(x9)
Days60.89PastDuelessthan0.SCORE =getscore(7,Days60.89PastDuelessthan0.WOE/10)
Days60.89PastDue0to1.SCORE =getscore(7,Days60.89PastDue0to1.WOE/10)
Days60.89PastDue1to3.SCORE = getscore(7,Days60.89PastDue1to3.WOE/10)
Days60.89PastDue3to5.SCORE = getscore(7,Days60.89PastDue3to5.WOE/10)
Days60.89PastDuemorethan.SCORE = getscore(7,Days60.89PastDuemorethan.WOE/10)
Days60.89PastDue.SCORE = c(Days60.89PastDuelessthan0.SCORE,Days60.89PastDue0to1.SCORE,
Days60.89PastDue1to3.SCORE,Days60.89PastDue3to5.SCORE,
Days60.89PastDuemorethan.SCORE)
Days60.89PastDue.SCORE
#NumberOfDependents变量(x10)
Dependentslessthan0.SCORE =getscore(8,Dependentslessthan0.WOE)
Dependents0to1.SCORE =getscore(8,Dependents0to1.WOE)
Dependents1to2.SCORE = getscore(8,Dependents1to2.WOE)
Dependents2to3.SCORE = getscore(8,Dependents2to3.WOE)
Dependents3to5.SCORE = getscore(8,Dependents3to5.WOE)
Dependentsmorethan.SCORE = getscore(8,Dependentsmorethan.WOE)
Dependents.SCORE = c(Dependentslessthan0.SCORE,Dependents0to1.SCORE,
Dependents1to2.SCORE,Dependents2to3.SCORE,
Dependents3to5.SCORE,Dependentsmorethan.SCORE)
Dependents.SCORE评分卡
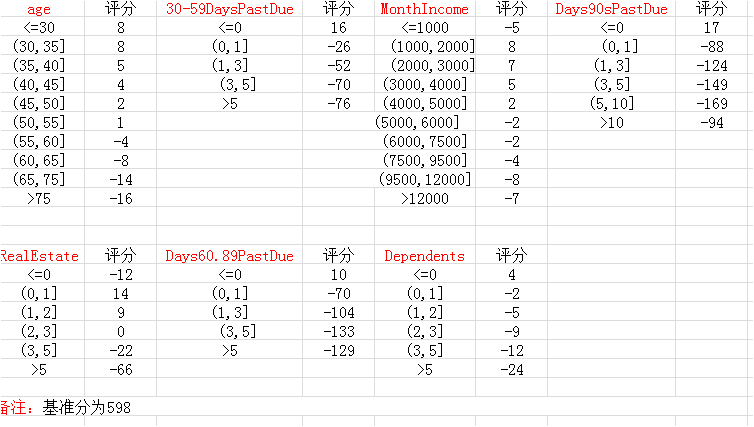

3.4.3一个示例
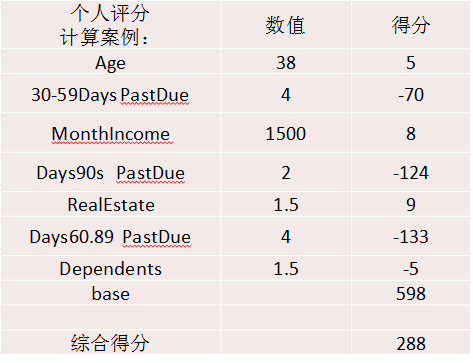

4.建立自动评分系统
自动评分系统示意代码
#计算每一个借款人的信用评分
#age
score.age <- 0
for(i in 1:nrow(train)) {
if(train$x2[i] <= 30)
score.age[i] <- Agelessthan30.SCORE
else if(train$x2[i] <= 35)
score.age[i] <- Age30to35.SCORE
else if(train$x2[i] <= 40)
score.age[i] <- Age35to40.SCORE
else if(train$x2[i] <= 45)
score.age[i] <- Age40to45.SCORE
else if(train$x2[i] <= 50)
score.age[i] <- Age45to50.SCORE
else if(train$x2[i] <= 55)
score.age[i] <- Age50to55.SCORE
else if(train$x2[i] <= 60)
score.age[i] <- Age55to60.SCORE
else if(train$x2[i] <= 65)
score.age[i] <- Age60to65.SCORE
else if(train$x2[i] <= 75)
score.age[i] <- Age65to75.SCORE
else
score.age[i] <- Agemorethan.SCORE
}
for(i in 1:nrow(train)){
creditScore[i]<-score.age[i]+score.PastDue[i]+score.MonthIncome[i]+
score.Days90PastDue[i]+score.RealEstate[i]+score.Days60.89PastDue[i]+
score.Dependents[i]+baseScore
}
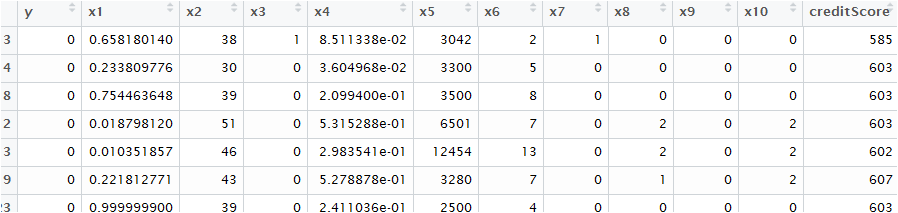
train$creditScore<-round(creditScore,0)自动评分系统可以批量计算信用评分

5.总结及展望
本文通过对kaggle上的Give Me Some Credit数据的挖掘分析,结合信用评分卡的建立原理,从数据的预处理、建模分析、创建信用评分卡到建立自动评分系统,创建了一个简单的信用评分系统。
基于AI 的机器学习评分卡系统可通过把旧数据(某个时间点后,例如2年)剔除掉后再进行自动建模、模型评估、并不断优化特征变量,使得系统更加强大。
